데이터베이스
Single Block I/O와 Multi Block I/O
캐시 모두 데이터를 적재해두면 속도도 빠르고 좋으나, 메모리에 한계가 있기 때문에 항상 적재하고 있을수는 없다. 그래서 캐시에서 찾지 못한 경우 I/O 콜을 사용하여 블록씩 데이터를 읽어들이는데 한번에 한 블록씩 가지고 오는 것을 Single Block I/O라고 한다. 그리고 여러 블록을 한번에 가지고 오는 것을 Multi Block I/O라고 한다. 기본적인 인덱스와 테이블 블록을 읽어들일때는 Single Block I/O 방식이 사용된다. 하지만 대량의 데이터를 테이블에서 가지고와야 할 때는 Multiblock I/O가 좋고 그 단위가 크면 대량의 블록에서 데이터를 한번에 가지고 올 수 있기에 프로세스가 잠자는 횟수를 줄일 수 있어 좋다. 그렇기 때문에 대용량 데이터를 Full Scan할때 Mult..

오라클의 논리적 I/O와 물리적 I/O의 차이 그리고 버퍼 캐시 히트율(BCHR) 구하기
오라클에서 SQL을 파싱하는 것을 내부에 저장하고 있는 라이브러리 캐시와 데이터를 캐시하고 있는 DB 버퍼캐시가 존재한다. 이 데이터를 저장하고 있는 캐시 또한 SGA의 중요한 요소 중 하나이다. 데이터 블록에 대해 캐시를 해두어서 다음번에 읽어들일때 같은 작업을 반복해서 하지 않도록 하는 기능을 제공한다. 그럼 이런 버퍼 캐시를 이용하여 처리하는 방식과 직접 디스크에 접근하여 데이터를 접근하는 방식에 차이는 무엇인지 알아보자. 논리적 I/O 와 물리적 I/O 오라클에서 SQL 문장을 처리하는 과정에는 두 가지 I/O가 존재한다. 하나는 논리적 블록 I/O 나머지는 물리적 블록 I/O이다. 논리적 I/O는 SQL 문장을 처리하는 과정에서 메모리 버퍼캐시에서 발생한 총 블록 I/O로써 메모리에 접근하여 데..

시퀀셜 액세스와 랜덤 액세스
데이터베이스에서 데이터를 블록단위로 읽는다. 1 ~ 3 byte와 같이 작은 데이터를 읽을때도 하나의 블록을 읽어들인다. 그리고 테이블뿐만 아니라 인덱스도 블록단위로 읽어들인다. 데이터베이스의 총 블록 사이즈를 알고 싶으면 다음 쿼리를 통해 확인해 볼 수있다.1select value from v$parameter where name = 'db_block_size';cs 그럼 테이블과 인덱스를 블록단위로 읽는 방식에 대해서 알아보자. 테이블 또는 인덱스를 읽는 방식 시퀀셜 액세스 (Sequential Access)논리적 또는 물리적으로 연결된 순서에 따라 차례대로 블록을 읽어들이는 방식이다. 인덱스 리프블록은 앞뒤를 가리키는 주소값으로 서로 연결되어 있는데 이를 이용하여 순차적으로 스캔하는 방식이다.테이블..

데이터 저장 구조 및 I/O 메커니즘
데이터베이스는 디스크로 구성되어있는 데이터베이스이기 때문에 SQL 튜닝은 곧 I/O 튜닝이다. 그렇기에 기본적인 데이터의 저장 구조 및 디스크 또는 메모리를 읽는 메커니즘에 대한 정리를 먼저 해보자. SQL 실행이 느려지는 이유 I/O가 처리되는 동안 다른 프로세스는 놀게된다. 그렇기 때문에 효율적인 프로세스 활용이 되지 못해 SQL이 느린 것이다. 왜냐하면 디스크에 접근하는 로직이 느린 경우 다른 프로세스는 계속 놀게되고 디스크 경합이 심해지기 때문이다. 데이터베이스 저장 구조데이터베이스를 저장하려면 먼저 테이블 스페이스를 만들어야 한다. 테이블 스페이스는 테이블, 인덱스, 파티션, LOB등 여러 세그먼트를 담는 컨테이너로써 여러 개의 데이터파일로 구성된다. 각 세그먼트는 데이터 저장공간이 필요한 오브..
바인드 변수를 이용한 오라클 SQL 튜닝 소개
저번 시간에 내부 프로시저를 재사용해야 쿼리 수행시 비용이 감소한다고 공부하였다. 그렇게 재사용성을 높이기 위해서 어떻게 해야하는지 알아보자. 바인드 변수 사용 사용자 정의 함수/프로시저, 트리거등은 별도의 이름이 있어 생성하여 계속해서 재사용할 수있다. 하지만 SQL은 이름이 없어서 내부 프로시저에 저장하여 사용한다. 그렇듯 SQL은 별도의 이름이 아닌 그 자체가 이름처럼 고유의 값으로 사용된다. 그럼 공백이나 대,소문자가 달라도 다른 객체인가? 아래 쿼리를보자. 12345678select * from t where empno = 7695;select * from t where empno = 7695 ; select * from T where empno = 7695;select * from t WHER..

오라클 옵티마이저의 소프트파싱(soft parsing)와 하드파싱(hard parsing)
소프트파싱와 하드파싱 이전장에서 설명하였듯이 옵티마이저가 쿼리를 수행하기 위해서 파싱, 최적화, 로우 소스 생성과정을 통해 내부 프로시저를 만든다. 이렇게 만든 내부프로시저를 반복해서 재사용할 수 있도록 캐싱해두는 메모리 공간을 라이브러리 캐시라고 한다. 라이브러리캐시는 System Global Area(SGA) 구성요소이다. SGA는 서버 프로세스와 백그라운드 프로세스가 공통으로 액세스하는 데이터와 제어 구조를 캐싱하는 메모리 공간이다. 사용자가 작성한 SQL 문장을 실행할 때 SGA에 캐시되어있는 내부 프로시저를 찾으면 바로 사용하는데 이를 소프트 파싱이라고 하고 내부 프로시저가 존재하지 않아 다시 처음부터 파싱, 최적화, 로우 소스 생성 단계를 거쳐야하는 것을 하드파싱이라고 한다. 그럼 소프트 파싱..
옵티마이저에게 사용할 인덱스(index) 힌트주기
기본적으로 옵티마이저가 SQL을 수행할 때 인덱스를 통계정보를 이용하여 선택하지만 그것은 정확한 것이 아니라 자신이 알고 있는 수준까지 정보를 가지고 판단하기에 정확한 인덱스를 사용자가 선택하여 수행할 수 있다. 그 방법으로 쿼리 수행시 힌트를 부여하는 것이다. 힌트를 부여하는 방법은 다음과같다.1select /*+ 인덱스명(t) */ * from t where deptno = 10 and no = 1;cs - /*+ 인덱스 */를 사용하여 힌트를 부여한다.- 인덱스명을 여러개 나열하고 싶을때는 공백으로 구분하여 나열한다. ,를 사용하는 경우 앞에 인덱스만 사용된다.- 인덱스 내부에 테이블을 적을때 스키마명까지 입력하면 안된다. index(scott.tmp)- From 절에 Alias를 사용했다면 힌트에..

SQL 최적화 과정과 옵티마이저 소개 및 역할안내
SQL 최적화 과정 오라클을 기준으로 SQL의 최적화 과정은 다음과 같다. 1. SQL 파싱-> 파싱트리 생성-> 문법적 오류 확인-> 의미상 오류 확인 (없는 컬럼, 테이블 접근)2. SQL 최적화-> 옵티마이저가 미리 수집한 시스템 및 오브젝트 통계정보를 바탕으로 가장 최적의 실행경로로 선정 3. 로우 소스 생성-> 선정된 실행경로를 실제 실행 가능 코드로 변경 (Row-Source Generator)가 역할 수행 그럼 이런 최적화를 진행하는 옵티마이저는 어떤것이고 또 어떻게 진행이되는가? SQL 옵티마이저란?- 옵티마이저는 사용자의 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 액세스 경로를 선택해주는 DBMS 엔진을 말한다. 최적화 단계 - 쿼리를 수행할 실행계획 찾기- Data Dicti..
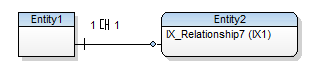
데이터 모델링 기초 설명
명칭 설명엔티티 -> 테이블속성 -> 컬럼인스턴스 -> 행 관계도1 대 N 1 대 1 M:N=> 모델링에서 M대 N은 아직 완성되지 않은 모델로 간주하여 1:N으로 전환시키는 작업을 진행하여야 한다. 참여도 표시|| 필수O 선택 => 사원은 부서를 필수로 포함해야하지만, 부서는 사원이 선택이다. 키 표시PK는 ◆ID 또는 ID(PK)와 같이 기재 (주 식별자)FK는 ID(FK)로 기재 Identifying과 Non-Identifying외래 식별자가 관계에 있는 다른 엔티티의 주 식별자의 일부일 경우 Identifying이라 하고 별도일 경우Non-Identifying 이라고 한다. => Identifying => Non-Identifying 요구사항을 통해 엔티티 정의 만들기 엔티티 정의 -> 먼저 명사..
엔티티 관계와 속성 추출 방법
새로운 속성으로 주 식별자 선정의 장 단점대출일, 회원번호, 도서관리번호를 주식별자로 가져야 하는 경우, 너무 많은 속성이 주 식별자가 되어 구별하기 어려울 때, 대출 번호라는 새로운 주 식별자를 도입할 수 있다.-> 하지만 새로운 주 식별자를 도입한경우, 다음과 같은 문제가 발생할 수 있다.-> 대출번호가 키가 되는경우 대출일, 회원번호, 도서관리번호가 중복된 데이터가 있을 수 있다.-> 새로운 개념의 속성을 만들어 주식별자로 지정할 경우 단점과 장점이 있으니 잘 사용해야 한다. 필요없는 속성을 주 식별자로 지정하는 경우.필요없는 속성이 주 식별자가 되는 경우, 문제가 발생할 수 있다.제품번호와 제품가격이 주 식별자가 되었을 때, 제품번호별로 제품가격은 하나여야 하는데 서로 다른 데이터가 존재할 수 있..