데이터베이스

Redis Keys 명령어의 대체 Scan 설명
Redis에서 Keys 명령어는 성능상으로 문제가 있다. Redis의 One Thread 정책으로 인해서 해당 작업을 처리하기 위해서 서버가 멈춰버린다. 그래서 이를 대안하기 위해서 Redis의 Scan이라는 기능을 사용할 수있다. Scan은 cusor를 기반으로 동작하는 Itorator이다. 처음시작은 scan 번호를 0으로 지정해서 시작한다. 그러면 두 개의 값을 반환을 하는데 첫번째 값은 다음 cursor의 번호이고 그 다음 값은 키값들이 출력된다. 다음 데이터를 찾기위해서는 1번 값에서 반환된 커서 값을 이용해서 검색하면 된다. (scan 9) 그리고 scan 후 나온 다음 cursor의 값이 0인경우 그 이후에 값이 없음을 의미한다. Option #Count Option scan은 모든 반복에서..

인덱스 생성 및 데이터 삽입
Elasticsearch에서 인덱스를 만들고 타입을 지정하여 데이터를 삽입하는 과정을 정리해보자. elasticsearch는 Restful API가 지원되기 때문에 BSL 쿼리를 이용하여 쉽게 데이터를 조작할 수 있다. 인덱스 생성Methd : put URLI : /{indexname}?pretty 생성된 인덱스 확인 Method : GET URI : _cat/indices?v kibana dev-tool에서 customer 인덱스가 생성된 것을 확인할 수 있다. 타입, Document 생성 및 데이터 추가 Method : PUT URI : /{indexname}/{typename}/[documentid]?pretty 만약 documentid를 넣지 않으면 랜덤으로 만들어서 삽입된다. 입력된 데이터 확인..

Docker Container에 Elasticsearch와 데이터 시각화 kibana 설치 및 연동
회사에서 사용하는 Elasticsearch 공부를 위해서 docker에 설치해보고 시각화에 도움주는 Kibana도 같이 설치해보자. 우선 Elasticsearch에 대한 기본 정보는 API 문서에서 확인할 수 있다. https://www.elastic.co/guide/kr/elasticsearch/reference/current/gs-index-query.html Elasticsearch 설치해당 이미지에는 xpack도 포함되어있다. xpack은 보안, 알림, 모니터링, 보고, 그래프 기능을 설치하기 편리한 단일 패키지로 번들 구성한 Elastic Stack 확장 프로그램이다. 우선 이미지를 내려받는다.1docker pull docker.elastic.co/elasticsearch/elasticsearc..
Elasticsearch 기본 정리
Definition- 엘라스틱서치는 색인 기능이 추가된 NoSQL DBMS이다.- Full Text Search(전문검색)과 문서의 점수화를 이용한 정렬, 데이터증가량에 구애받지 않는 실시간 검색 등을 제공- 여러개의 노드로 구성된 분산시스템이다. 각 노드는 데이터를 색인하고 검색기능을 수행하는 단위 프로세스이다. 각 노드는 복사본과 원본을 다른 위치에 저장하고 있어서 안전하다.- 검색 시 서로 다른 인덱스의 데이터를 바로 하나의 질의로 묶어서 여러 검색 결과를 하나의 출력으로 도출할 수 있는 멀티 테넌시를 제공한다.- 모든 데이터는 JSON 구조로 저장된다.- RestFul API를 지원하므로 URI를 사용한 동작이 가능. (이런 Restful api를 활용한 쿼리를 dsl 쿼리라고 한다.) 용어Ind..
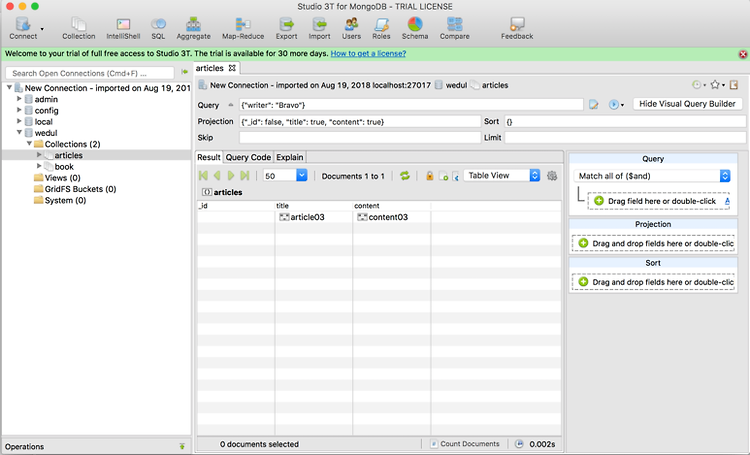
Docker에 MongoDB 설치 후 Studio 3T로 접속해서 쿼리 사용해보기
Docker에 MongoDB를 설치하고 무료 접속 툴인 Studio 3T를 이용해서 접속해보고 쿼리를 사용해보자. 1. Docker에 MongoDB 설치Docker에서 MongoDB 설치를 위해 필요한 내용을 docker-compose.yml 파일을 만든다.1234567891011121314version: '3' services: mongodb: image: mongo:latest container_name: "mongodb" environment: - MONGO_DATA_DIR=/data/db - MONGO_LOG_DIR=/dev/null ports: - 27017:27017 volumes: - /Users/wedul/Documents/docker/datafile/mongodb/:/data/db Col..

Mysql 묵시적 형변환
묵시적 형변환 조건절의 데이터 타입이 다를 때 우선순위가 높은 타입으로 형이 내부적으로 변환 되는 것. 정수 > 문자열 순이며 만약 정수와 문자열이 비교가 되는 경우에는 둘중에 우선순위가 낮은 것이 변경된다. 우리는 이렇게 자동으로 형변환 해주는 경우에 익숙해져 있다. 자바에서도 Integer와 int 두 개의 변수의 값을 묵시적으로 형변환 시켜주지만 이는 이펙티브 자바 책에서도 볼 수 있지만 성능저하의 원인이 된다고 한다. Mysql도 예외가 아닌 것 같다. 예를 들어 보자 아래와 같은 테이블을 생성 후 데이터를 삽입한다. 1234567891011121314151617181920212223# 테이블 생성 create table chagne_data ( id int unsigned not null aut..

Mysql 실행계획 설명
프로그램의 성능을 높히기 위해서는 DB튜닝이 필요하다. Mysql에서 튜닝을 하기 위해서 제공하는 쿼리의 실행 계획에 대해 정리해보자. Mysql의 데이터 처리 방식우선 Mysql의 데이터 처리방식에 대해 정리해보자. - Mysql은 단일 코어로 데이터를 처리하기 때문에 멀티코어로 scale out을 진행하는 것 보다 cpu 자체의 성능을 높히는 scale up을 하는 것이 더 효율적이다. - Oracle과 달리 mysql은 nested loop join 알고리즘만 사용한다. - Nested Loop Join은 선행 테이블의 검색 결과 값 하나하나 테이블 B와 조인하는 방식이다. 그래서 데이터 양이 적을 때는 상관이 없으나 데이터가 많은 테이블끼리 조인할 시 성능에 문제가 있을 수 있다. 그래서 내부적으..

Mysql Exists와 IN절 설명과 차이점
두 개 모두 where절에 조건을 보고 결과를 걸러낼때 사용하는데 정리가 잘 안되서 정리해봤다. Exists 서브쿼리가 반화나는 결과값이 있는지를 조사한다. 단지 반환된 행이 있는지 없는지만 보고 값이 있으면 참 없으면 거짓을 반환한다.1SELECT * FROM sample1;cs1SELECT * FROM sample2;cs 두 개의 테이블중 조건에 맞는 Row만 추출된다. 1SELECT * FROM sample1 s1 WHERE EXISTS(SELECT * FROM sample2 s2 WHERE s1.no = s2.no);cs그럼 반대로 조건에 맞지 않는 ROW만 추출하고 싶으면 어떻게 해야할까?1SELECT * FROM sample1 s1 WHERE NOT EXISTS(SELECT * FROM sam..

Mysql의 서버엔진과 스토리지 엔진
Mysql에는 두 가지 형태의 엔진이 존재한다. 아래 그림에서 보면 하단에 길게 표시된 Pluggable 스토리지 엔진을 제외하고 위에 모든 부분이 서버엔진이다. 엔진별 특징 정리서버엔진 (SQL Interface, Parser, Optimizer, Cache & Buffer) - 클라이언트의 요청을 받아 SQL을 처리하는 DB 자체의 기능적인 역할을 수행 - DB가 SQL을 이해할 수 있도록 쿼리를 파싱하고 메모리, 물리적 저장장치와 통신하는 기능을 수행 - 디스크와 직접적인 접근을 제외한 대부분의 역할 수행 스토리지 엔진 - 서버 엔진이 필요한 데이터를 물리적 장치에서 가지고 오는 역할을 수행 - 물리적 저장장치에서 데이터를 읽어오는 역할을 수행하고 플러그인 형식으로 여러 스토리지 엔진을 필요에 따라..

SELECT-LIST 컬럼 가공시 정렬연산 수행 확인 및 개선방법
인덱스가 Id, ch_date, ch_order 순으로 생성되어 있을 경우 MIN 값을 구해도 별도의 정렬연산을 수행하지 않는다. 수직적 탐색을 통해서 가장 왼쪽지점에서 보는 최소 값이 바로 구하고자 하는 값이기 때문이다. 1SELECT MIN(ch_date) FROM scott.SORT_TEST WHERE ID = ‘C’;csMAX의 경우도 마찬가지이다. MIN과 다른 점은 왼쪽에서 찾는게 아니라 가장 오른쪽에 있는 데이터를 찾는다는 점이다.1SELECT MAX(ch_date) FROM scott.SORT_TEST WHERE ID = ‘C’;cs 그래서 두 개의 실행계획을 살펴보면 인덱스 리프 블록의 왼쪽(MIN) 또는 오른쪽 (MAX)에서 레코드 하나(FIRST ROW)만 읽고 멈춘다.1SELECT ..