데이터베이스/Nosql

Line 세미나. Redis Pub/Sub을 사용해 대규모 사용자에게 고속으로 설정 정보를 배포한 사례
개요 - Line Live chat은 Akka로 동작하며 client와 server사이에는 웹소켓으로 동작 - 120대의 채팅 서버와 사이의 커뮤니케이션은 redis pub/sub을 사용 - 채팅의 임시데이터는 레디스에 저장하고 영속 데이터는 정규화해서 배치를 통해 mysql에 저장 - 유저와 시스템을 통해 일부 코멘트를 제어하기도 함 기존 아키텍처 소개 - 방송자가 시청자를 차단하는 경우 차단된 시청자의 코멘트를 해당 방송에서 보여지지 않도록 하는 기능이 있다. - 방송자가 api에 특정 사용자 차단을 요청하면 block 정보를 디비에 저장하고 chat internal api서버에 차단 정보를 전송한다. - 전송 받은 internal 서버는 정보를 mysql에 저장한다. - 웹소켓은 로컬캐시를 뒤지고 ..
Redis Cluster mode에서 mget, mset, pipeline과 같은 멀티 키 명령어 사용하기.
redis에 만약 200 ~ 300개가 넘는 캐시 정보를 계속 request를 날리면 레이턴시가 발생할 가능성이 크기 때문에 이런경우에 mget, mset, pipeline 등 멀티키 명령어를 사용한다. 하지만 redis가 single mode일 때는 아무 상관이 없지만 cluster mode인경우에는 다음과 같은 오류를 발생 시킨다. "CROSSSLOT Keys in request don't hash to the same slot" 무슨 오류일까?? 처음에 redis가 싱글모드로 돌고 있던 stage에서 테스트를 해서 정상적으로 멀티키 명령어가 잘 되는줄 알고 배포 했다가 라이브에서 위와 같은 오류가 발생했다... 너무 당황해서 바로 수정했다. 무엇이 문제 였을까? 하면서 문서를 찾아보니 redis에는..

redis cluster로 구성하여 실행 시켜보기
redis를 사용하면서 cluste로 구성해봐야하는 일이 있었다. 그래서 찾아보던 중 redis문서에서 방법을 찾았다. https://redis.io/topics/cluster-tutorial Redis cluster tutorial – Redis *Redis cluster tutorial This document is a gentle introduction to Redis Cluster, that does not use complex to understand distributed systems concepts. It provides instructions about how to setup a cluster, test, and operate it, without going into the detai re..
[번역] Redis partitioning
파티셔닝 공부를 위해 아래 페이지의 내용을 번역하며 정리해봤다.https://redis.io/topics/partitioning Redis Partitioning: 여러 레디스 인스턴스로 데이터 분배하기 파티셔닝은 데이터를 여러 레디스 인스턴스로 분할하여 모든 인스턴스가 자기가 소유한 키의 집합들만 소유하도록 하는 프로세스이다. 먼저 파티셔닝 개념에 대해 설명하고 레디스 파티셔닝에 대한 대안을 소개한다. 파티셔닝이 효율적인 이유 레디스에서 파티셔닝을 하기는 다음 두개의 이점이 있다. 1. 하나의 컴퓨터로 메모리의 양이 제한되는 경우에 파티셔닝을 사용하여 더 큰 데이터베이스와 메모리를 가질 수 있다. 2. 여러 개의 코어와 여러 대의 컴퓨터에 연산 능력을 확장하고 네트워크 대역폭을 여러 대의 컴퓨터와 네트..

Redis Keys 명령어의 대체 Scan 설명
Redis에서 Keys 명령어는 성능상으로 문제가 있다. Redis의 One Thread 정책으로 인해서 해당 작업을 처리하기 위해서 서버가 멈춰버린다. 그래서 이를 대안하기 위해서 Redis의 Scan이라는 기능을 사용할 수있다. Scan은 cusor를 기반으로 동작하는 Itorator이다. 처음시작은 scan 번호를 0으로 지정해서 시작한다. 그러면 두 개의 값을 반환을 하는데 첫번째 값은 다음 cursor의 번호이고 그 다음 값은 키값들이 출력된다. 다음 데이터를 찾기위해서는 1번 값에서 반환된 커서 값을 이용해서 검색하면 된다. (scan 9) 그리고 scan 후 나온 다음 cursor의 값이 0인경우 그 이후에 값이 없음을 의미한다. Option #Count Option scan은 모든 반복에서..
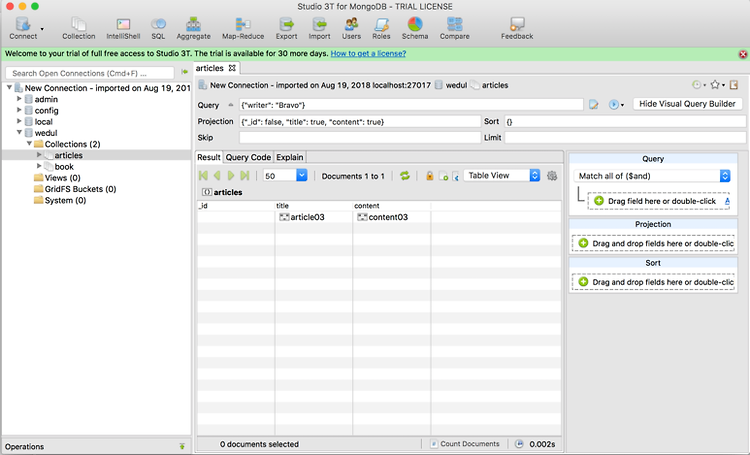
Docker에 MongoDB 설치 후 Studio 3T로 접속해서 쿼리 사용해보기
Docker에 MongoDB를 설치하고 무료 접속 툴인 Studio 3T를 이용해서 접속해보고 쿼리를 사용해보자. 1. Docker에 MongoDB 설치Docker에서 MongoDB 설치를 위해 필요한 내용을 docker-compose.yml 파일을 만든다.1234567891011121314version: '3' services: mongodb: image: mongo:latest container_name: "mongodb" environment: - MONGO_DATA_DIR=/data/db - MONGO_LOG_DIR=/dev/null ports: - 27017:27017 volumes: - /Users/wedul/Documents/docker/datafile/mongodb/:/data/db Col..