docker
Junit5 Test Container사용하여 테스트 환경 구축하기 (인프런 백기선님 강의 정리)
도커와 테스트 (TestContainers) 테스트를 위해서는 운영과 동일한 형태의 개발 환경에서 테스트 하는 것이 중요하다. 하지만 매번 동일하게 환경을 구축할 수 없고 모든 개발 자들과 같은 환경을 맞추기도 쉽지 않다. 그래서 Docker를 이용해서 테스트마다 테스트를 위한 컨테이너를 실행시켜서 테스트하고 컨테이너를 제거해주면 좋은데 그런 기능을 TestContainer를 이용해서 가능하다. 실제로 이번에 이직한 회사에서 동일하게 테스트 환경을 사용하는 것을 봤다. 막연하게 그 기능을 사용할 수 있었지만 이번 Junit5 백기선님 강의를 들어서 확실하게 정리할 수 있어서 좋았다. 역시 듣길 잘했다. 꼭 들어보길 강추한다. 그럼 그 내용을 정리해보자. 테스트 컨테이너(Test Container) 라이브..

nginx 서버에 filebeat를 이용하여 ELK에 로그 기록하기
git clone https://github.com/deviantony/docker-elk nginx를 설치하고 docker 기반으로 ELK (elasticsearch, logstash, kibana)를 설치하고 nginx 로그를 filebeat를 설치하여 acces.log, error.log, syslog등을 전송해보자. 설치 ELK를 도커에 설치하는 스크립트를 아래 github에 잘 정리되어 제공해주고 있다. https://github.com/deviantony/docker-elk ELK는 이걸로 설치하면 되는데 docker-compose로 nginx와 filebeat까지 함께 설치하기 위해서 아래 저장소에서 제공하는 nginx-filebeat 스크립트를 혼합해서 사용해보자. https://githu..

kubernetes 기본 개념정리와 구성 알아보기 (설치 포함)
docker를 사용하면서 그 편리함을 느끼고 있었다. 그리고 요 근래 it회사에서 docker와 kubernets를 이용하여 인프라를 운영을 하는 것을 많이 들었다. 나는 그런 환경을 접해보지는 못했기 때문에 정확하게 kuberntes가 무엇인지 잘 모른다. 그래서 이번 기회에 kubernets(이하 쿠버네티스)에 대한 기본 개념을 정리하고 설치해서 공부를 위한 초석을 닦아보자. 쿠버네티스 (kubernetes) 쿠버네티스는 도커 컨테이너 운영을 자동화 하기위한 오케스트레이션 도구이다. 구글에서 만들었으며 컨테이너를 운영하고 다루기 위한 api와 cli등을 제공한다. 컨테이너 배포 이외에도 효율적인 컨테이너 배치 및 스케일링, 로드밸런싱, 헬스 체크, secure등의 기능을 제공한다. AWS ECS 와 ..

elasticsearch 7.0 docker 설치 후 변경사항 확인
엘라스틱서치 7.0이 출시했다. 엘라스틱서치 7.0에는 kibana UI변경과 multi mapping type 제거 등의 이슈가 있다. 우선 달라진점을 확인하기 위해 docker에 설치해보자. 설치 elasticsearch docker run --name elastic7.0 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.0.0 kibana docker run -d --rm --link elastic7.0:elastic-url -e "ELASTICSEARCH_HOSTS=http://elastic-url:9200" -p 5601:5601 --name kibana7...

가정용 synology nas ds118 개봉기!!
집에서 개인적으로 사용할 nas를 구입했다. 간단하게 파일 저장하고 공유하고 docker를 사용해서 mysql, redis등을 사용하기 위해서 구입했다. 위메프에서 ds118 20만원에 구입하고 wd 1tb nas용 하드를 구입했다. 구입은 맥을 사면서 적립되었던 포인트를 사용해서 실질적으로 구매비용은 10만원정도 들었다. 사실 하드를 nas용으로 사야하나 싶었으나 인터넷에 알아보니 nas에 일반 하드를 설치하면 고장날 확률이 많다고 한다. 대표적으로 nas에 경우 24시간 켜져있고 진동이 하드에 전달되기 때문에 고장난 확률이 높아진다고 한다. 그래서 nas 하드를 위메프에서 7만원에 구매했다. 박스는 안전하게 포장되어 왔다.생각보다 가볍다. 비싼 제품인데 봉인 씰이 없는건 아쉽다. 내부를 뜯어보면 어댑..

Spring Boot에서 6.4 Elasticsearch 연결 및 간단 CRUD
Elasticsearch를 Spring Boot에서 작업을 하는 간단한 정리를 해보자. 1. Library 추가Elasticsearch를 사용하기 위해서는 spring-data-elasticsearch 라이브러리가 추가되어야 한다. gradle에 추가해보자.1234567dependencies { implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch' implementation 'org.springframework.boot:spring-boot-starter-web' testImplementation 'org.springframework.boot:spring-boot-starter-test' compileOnly "o..

Docker Container에 Elasticsearch와 데이터 시각화 kibana 설치 및 연동
회사에서 사용하는 Elasticsearch 공부를 위해서 docker에 설치해보고 시각화에 도움주는 Kibana도 같이 설치해보자. 우선 Elasticsearch에 대한 기본 정보는 API 문서에서 확인할 수 있다. https://www.elastic.co/guide/kr/elasticsearch/reference/current/gs-index-query.html Elasticsearch 설치해당 이미지에는 xpack도 포함되어있다. xpack은 보안, 알림, 모니터링, 보고, 그래프 기능을 설치하기 편리한 단일 패키지로 번들 구성한 Elastic Stack 확장 프로그램이다. 우선 이미지를 내려받는다.1docker pull docker.elastic.co/elasticsearch/elasticsearc..
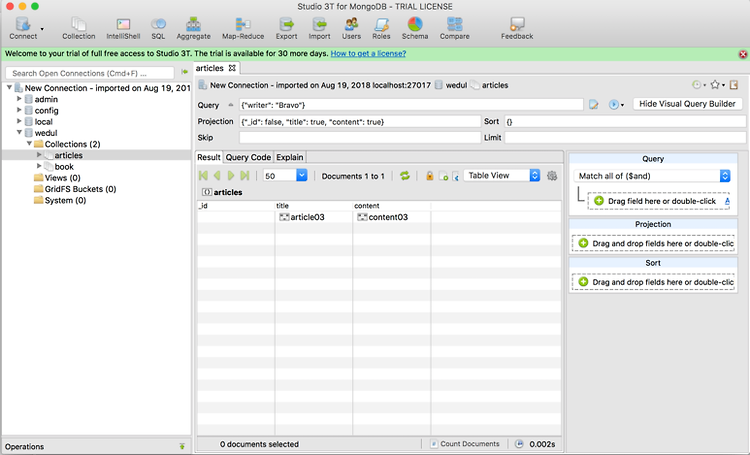
Docker에 MongoDB 설치 후 Studio 3T로 접속해서 쿼리 사용해보기
Docker에 MongoDB를 설치하고 무료 접속 툴인 Studio 3T를 이용해서 접속해보고 쿼리를 사용해보자. 1. Docker에 MongoDB 설치Docker에서 MongoDB 설치를 위해 필요한 내용을 docker-compose.yml 파일을 만든다.1234567891011121314version: '3' services: mongodb: image: mongo:latest container_name: "mongodb" environment: - MONGO_DATA_DIR=/data/db - MONGO_LOG_DIR=/dev/null ports: - 27017:27017 volumes: - /Users/wedul/Documents/docker/datafile/mongodb/:/data/db Col..

Windows Subsystem for Linux (ubuntu)에 Docker 설치
맥에서는 docker 설치와 운용이 쉬웠는데, 맥북이 망가지고 윈도우 컴퓨터를 사용하고 있으니 Docker 사용이 생각보다 쉽지 않았다. 그래서 저번에 Windows Subsystem for linux (ubuntu)를 설치하고 여기에 docker를 올려보면 어떨까 싶어서 도전해 보았다. 우선 docker engine는 WSL에서 실행되지 않아서 호스트 컴퓨터에 Windows용 Docker를 설치해야한다. 그리고 나서 Linux(ubuntu)에서 실행되는 Docker 클라이언트(WSL)가 Windows에 설치된 Docker Engine 데몬으로 명령어를 보내서 운용할 수 있다. 우선 Ubuntu에 Docker를 설치해보자. 1. 우선 패키지를 업데이트 한다.1sudo apt-get updatecs 2. ..
Spring Boot 빌드 파일을 이미지로 만들어 컨테이너에 올리기.
스프링 부트 애플리케이션을 Docker image로 빌드해서 컨테이너에 올리는 작업을 진행해 보겠다. 필요사항 JDK 1.8 later Maven 3.2 이상 STS Docker Pom.xml 수정을 먼저 진행해야한다. wedul 이라는 이름의 jar 파일이 생성된다. docker에서 실행하기 위한 Maven 설정이 들어있는 jar file이 만들어 진다. 만약 image prefix 값을 별도로 지정하지 않으면 artifact id가 명시된다. wedul com.spotify dockerfile-maven-plugin 1.3.6 ${docker.image.prefix}/${project.artifactId} target/${project.build.finalName}.jar 그리고 프로젝트 Root에 ..