설명

Mysql 인덱스 사용법 및 실행 계획 정리
mysql 인덱스에 대한 정확한 이해도 없이 사용을 하다보니 조금 개념적으로 헷갈리는게 많이 있었다. 이 부분에 대해 한번 정리하고 넘어가고자 기록해본다. 인덱스 인덱스는 빠르게 특별한 컬럼과 함께 값을 찾는데 사용된다. 인덱스가 없으면 Mysql은 처음 행부터 전체 테이블을 읽어 들여서 데이터를 찾는다. 거대한 테이블에서 이런 행동은 비용이 상당히 많이 들어가게 된다. 만약에 테이블이 인덱스를 가지고 있으면 빠르게 접근할 수 있게 된다. 대부분의 Mysql 인덱스 (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT)는 B-tree안에 저장된다. 예외적으로 spatial 데이터 타입은 R-tree를 사용, 메모리 테이블은 또한 hash index를 지원, InnoDB는 FULLTE..

Spring5 리액티브 스트림 정리 및 api 전달 방식 정리
리액티브 또는 리액티브 스트림은 오늘날 spring framework에서 뜨거운 토픽으로 자리잡고 있다. 그래서 나도 이전 포스팅에서도 정리도 하고 했었는데 아직 확실히 개념이 서질 않아서 다시 정리해봤다. 리액티브 스트림 (Reactive Stream) 이란? 리액티브 스트림은 무엇인가? 정확하게 공식문서에는 다음과 같이 기록되어 있다. (https://www.reactive-streams.org/) Reactive Streams is an initiative to provide a standard for asynchronous stream processing with non-blocking back pressure.This encompasses efforts aimed at runtime enviro..
[번역] Redis partitioning
파티셔닝 공부를 위해 아래 페이지의 내용을 번역하며 정리해봤다.https://redis.io/topics/partitioning Redis Partitioning: 여러 레디스 인스턴스로 데이터 분배하기 파티셔닝은 데이터를 여러 레디스 인스턴스로 분할하여 모든 인스턴스가 자기가 소유한 키의 집합들만 소유하도록 하는 프로세스이다. 먼저 파티셔닝 개념에 대해 설명하고 레디스 파티셔닝에 대한 대안을 소개한다. 파티셔닝이 효율적인 이유 레디스에서 파티셔닝을 하기는 다음 두개의 이점이 있다. 1. 하나의 컴퓨터로 메모리의 양이 제한되는 경우에 파티셔닝을 사용하여 더 큰 데이터베이스와 메모리를 가질 수 있다. 2. 여러 개의 코어와 여러 대의 컴퓨터에 연산 능력을 확장하고 네트워크 대역폭을 여러 대의 컴퓨터와 네트..

nginx 정리와 설치 및 기본 설정방법
Ngnix 설명nginx는 기존 웹서버에서 많은 트래픽을 감당하기 위해서 확정성을 가지고 설계된 비동기 이벤트 드라이븐 방식의 웹서버를 칭한다. Nginx 설치nginx를 맥이 있으면 brew를 통해서 간단하게 설치가 가능하다.1brew install nginxcs Nginx 프로세스nginx는 하나의 마스터 프로세스와 여러 worker 프로세스를 가진다. 마스터 프로세스의 주요 목적은 read 권한 그리고 성능 측정과 worker 프로세스 관리이다. worker 프로세스는 요청을 처리한다. nginx는 event-based 모델을 사용하고 worker 프로세스 사이에 요청을 효율적으로 분배하기 위해서 os에 의존하는 매커니즘을 사용한다. worker 프로세스에 개수는 설정 파일에서 정의되며 정의된 프로..
Elasticsearch 기본 정리
Definition- 엘라스틱서치는 색인 기능이 추가된 NoSQL DBMS이다.- Full Text Search(전문검색)과 문서의 점수화를 이용한 정렬, 데이터증가량에 구애받지 않는 실시간 검색 등을 제공- 여러개의 노드로 구성된 분산시스템이다. 각 노드는 데이터를 색인하고 검색기능을 수행하는 단위 프로세스이다. 각 노드는 복사본과 원본을 다른 위치에 저장하고 있어서 안전하다.- 검색 시 서로 다른 인덱스의 데이터를 바로 하나의 질의로 묶어서 여러 검색 결과를 하나의 출력으로 도출할 수 있는 멀티 테넌시를 제공한다.- 모든 데이터는 JSON 구조로 저장된다.- RestFul API를 지원하므로 URI를 사용한 동작이 가능. (이런 Restful api를 활용한 쿼리를 dsl 쿼리라고 한다.) 용어Ind..
node.js express 모듈 - router
Express 모듈은 node.js에서 핵심 모듈인 http와 connect 컴포넌트를 기반으로 하는 웹 프레임워크이다. 여기서 사용되는 router 기능에 대해 정리해보자.기본적으로 express 모듈을 사용하기 위해서는 다음과 같이 모듈을 로드해야한다. router 의 기본 형태는 다음과 같다. 123456const express = require('express');const router = express(); // 기본 동작 형태router.get('/' , (req, res, next) => { });Colored by Color Scriptercs 기본 router 등록은 위와 같다. http 요청 메서드에 따라 메서드의 이름은 post, put, delete등으로 변경해서 사용하면 되고 첫번..

Mysql Exists와 IN절 설명과 차이점
두 개 모두 where절에 조건을 보고 결과를 걸러낼때 사용하는데 정리가 잘 안되서 정리해봤다. Exists 서브쿼리가 반화나는 결과값이 있는지를 조사한다. 단지 반환된 행이 있는지 없는지만 보고 값이 있으면 참 없으면 거짓을 반환한다.1SELECT * FROM sample1;cs1SELECT * FROM sample2;cs 두 개의 테이블중 조건에 맞는 Row만 추출된다. 1SELECT * FROM sample1 s1 WHERE EXISTS(SELECT * FROM sample2 s2 WHERE s1.no = s2.no);cs그럼 반대로 조건에 맞지 않는 ROW만 추출하고 싶으면 어떻게 해야할까?1SELECT * FROM sample1 s1 WHERE NOT EXISTS(SELECT * FROM sam..
자바 Annotation 만들기
자바에서 Annotation은 별도의 properties파일이나 xml같은 설정파일에 작성하는 부가적인 정보를 어노테이션으로 간편하게 설정할 수 있다. 형태 123456789101112131415@Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface Anno { public String defaultVal() default “OK”; public String val(); } Colored by Color Scriptercs Target은 어노테이션의 적용 대상을 선정하고, Retension은 이 어노테이션의 정보가 어디 까지 유지되는지 설정한다. @Target - Constructor, Field..
NAT와 DHCP설명 및 차이점
NAT : Network address translation(네트웍 주소 변환) IPv4에서는 IP주소가 부족하고 보안상에 몇가지 문제가 있어서, 점점 더 많은 네트웍에서 인터넷에서 사용할 수 없는 사설 IP(10.0.0.0/255.0.0.0, 172.16.0.0/255.240.0.0 , 192.168.0.0/255.255.0.0)를 사용하고 있다. 사설망에 있는 호스트에서 인터넷에 접속을 하거나 인터넷망에서 사설망의 호스트에 접속하기 위해서 NAT(network address translation)기능이 필요하다. NAT는 특정한 IP 주소를 한 그룹에서 다른 그룹으로 매핑하는 기능이다. 주소를 N-to-N 형태로 매핑하는 경우를 정적 NAT라 하고 M-to-N(M>N)를 동적 NAT라고 한다. 네트웍..
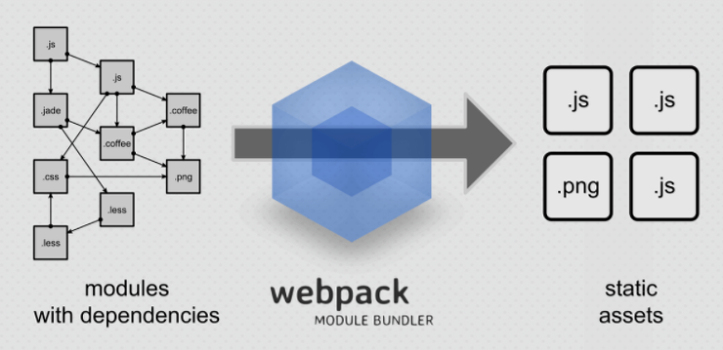
webpack 소개 및 환경 구축
Webpack - webpack은 모듈 번들러이다.- 여러 js 파일을 하나의 번들로 만들 수 있다.- SCSS를 CSS로 돌릴 수 있다.- EM6를 사용할 수 있다.- 스타일로더와 CSS 로더등 다양한 로더를 사용할 수 있다.- 코드 압축을 해주는 UglifyJsPlugin 등 다양한 플러그인등을 사용할 수 있다. 설치방법- node.js를 설치한다. https://nodejs.org/ko/ - npm install -g webpack (npm을 이용하여 webpack을 설치한다)- npm install --save-dev style-loader css-loader (css loader)- npm install --save-dev sass-loader node-sass webpack (scss load..