
elasticsearch에서는 들어온 요청에 대해서 primary shard, replica shard를 병렬로 요청을하기 때문에 replica가 있는게 좋긴하다. 하지만 replica shard나 primary shard가 제대로 노드에 분배되어 있지 않으면 조회가 특정노드에 몰리거나 인덱싱 시 노드에 부하가 심해질 수 있다.
분배를 위해서는 기본적으로 es cluster에 아래 옵션들이 제공된다. (링크)
cluster.routing.allocation.balance.shard
- 노드에 샤드를 균등하게 분배 (기본값 0.45f, 값이 높아질수록 노드들에 샤드들이 골고루 분배됨)
cluster.routing.allocation.balance.index
- 인덱스당 샤드 분배를 균등하게 (기본값은 0.55f, 값이 높아질후록 클러스터 모든 노드에 shard가 골구루 분배됨)
cluster.routing.allocation.balance.threshold
- 클러스터에서 노드 간 데이터 분배를 조정하는데 사용한다. (기본값은 1.0f, 이값이 높아지면 높아질 수록 클러스터는 밸런스가 깨진 상태가 됨)
하지만 위 설정을 한다고 해도 일부 샤드만 재조정을 하고자하는 경우가 있을것이다. 관련해서 우리는 reroute api를 사용할것이고 몇가지 사례를 가정해서 테스트 해보자.
primary shard를 노드를 이동하고 싶을 때
primary shard가 3개있고 노드가 3개인 상황에서 shard0을 elasticsearch3 node로 move시켜보자.

POST _cluster/reroute
{
"commands": [
{
"move": {
"index": "wedul",
"shard": 0,
"from_node": "elasticsearch1",
"to_node": "elasticsearch3"
}
}
]
}
shard 0이 elasticsearch 3로 이동되고 1이 elasticsearch0으로 swap 된거를 확인할 수 있다.
그럼 primary shard가 수가 노드마다 다를때는?

0을 elasticsearch2노드로 옮겨보자.

POST _cluster/reroute
{
"commands": [
{
"move": {
"index": "wedul2",
"shard": 0,
"from_node": "elasticsearch1",
"to_node": "elasticsearch2"
}
}
]
}샤드가 한쪽이 더 많을 때는 스왑되지 않고 그대로 옮겨진다.
그럼 샤드가 할당되지 않은 노드에 할당한다면?

POST localhost:19200/_cluster/reroute
{
"commands": [
{
"move": {
"index": ".ds-.logs-deprecation.elasticsearch-default-2023.07.25-000001",
"shard": 0,
"from_node": "elasticsearch7",
"to_node": "elasticsearch4"
}
}
]
}잘 옮겨진다.

replica가 있는 상태에서 primary shard를 노드를 이동하고 싶을 때
replica shard가 1개로 primary shard를 이동시켜보자. elasitcsearch3에 있는 1번 shard를 elasticsearch2 샤드로 옮겨보자.
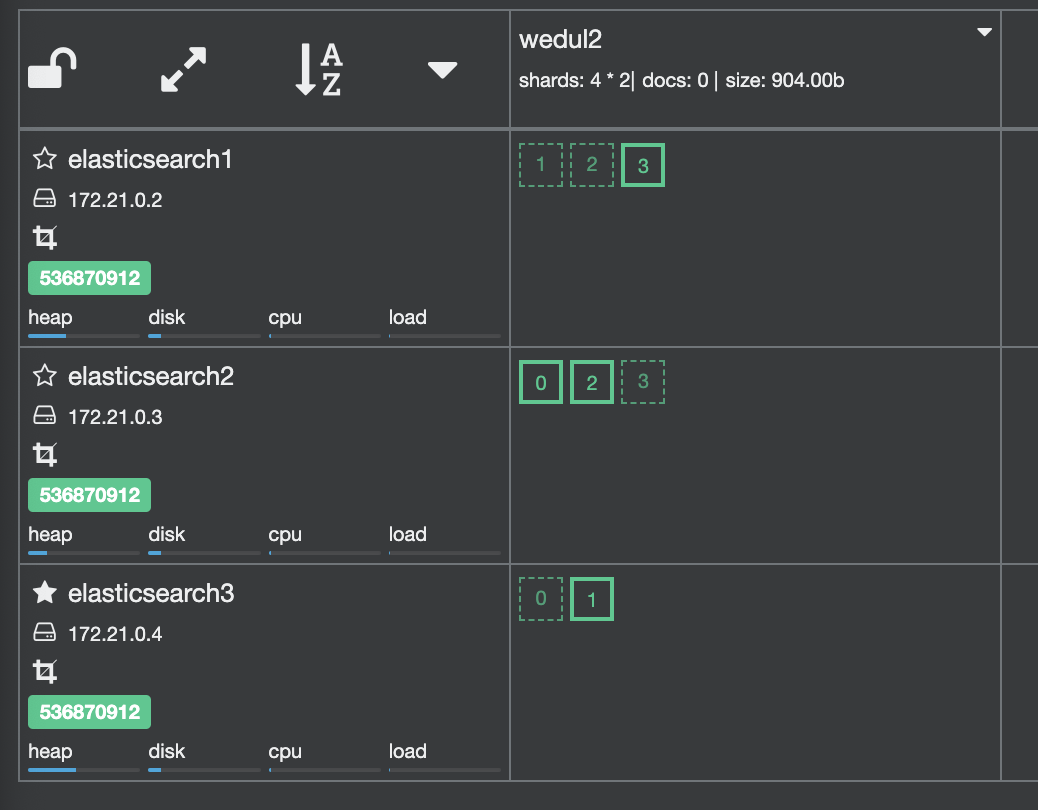
POST _cluster/reroute
{
"commands": [
{
"move": {
"index": "wedul2",
"shard": 1,
"from_node": "elasticsearch3",
"to_node": "elasticsearch2"
}
}
]
}
1번 샤드가 옮겨지면서 elasticsearch2에 있던 3 replica shard가 옮겨지는 rebalance가 진행되었다.
그럼 이번에는 primary shard가 없는 노드로 primary shard를 보내보자.
elasticseearch2에 있는 primary shard2를 elasticsearch3로 이동시키면 아래와 같이 조정이되었다. 그럼 아래상태에서 다시 shard 1을 elasticsearch2로 옮겨보는 command를 날려보자.

POST /_cluster/reroute
{
"commands": [
{
"move": {
"index": "wedul2",
"shard": 1,
"from_node": "elasticsearch3",
"to_node": "elasticsearch2"
}
}
]
}아까와는 다르게 실패하게 되는데 원인을 로그에서 확인해보자.
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "[move_allocation] can't move 1, from {elasticsearch3}{T-R4unaNTrS3cG0TBLZI1w}{VnPxLF9MSSyY2i5v28y34w}{172.21.0.4}{172.21.0.4:9300}{cdfhilmrstw}{ml.machine_memory=8232894464, xpack.installed=true, transform.node=true, ml.max_open_jobs=512, ml.max_jvm_size=536870912}, to {elasticsearch2}{fZmPapXcTmOXUZW5qgY37g}{5BmI1q8hS8SBr6Pn7itftw}{172.21.0.3}{172.21.0.3:9300}{cdfhilmrstw}{ml.machine_memory=8232894464, ml.max_open_jobs=512, xpack.installed=true, ml.max_jvm_size=536870912, transform.node=true}, since its not allowed, reason: [YES(shard has no previous failures)][YES(shard is primary and can be allocated)][YES(explicitly ignoring any disabling of allocation due to manual allocation commands via the reroute API)][YES(can relocate primary shard from a node with version [7.17.5] to a node with equal-or-newer version [7.17.5])][YES(no snapshots are currently running)][YES(ignored as shard is not being recovered from a snapshot)][YES(this node is not currently shutting down)][YES(neither the source nor target node are part of an ongoing node replacement (no replacements))][YES(node passes include/exclude/require filters)][NO(a copy of this shard is already allocated to this node [[wedul2][1], node[fZmPapXcTmOXUZW5qgY37g], [R], s[STARTED], a[id=YXQNS0DQTbqQ0yAh6AtE7Q]])][YES(enough disk for shard on node, free: [49.3gb], shard size: [3.3kb], free after allocating shard: [49.3gb])][YES(below shard recovery limit of outgoing: [0 < 2] incoming: [0 < 2])][YES(total shard limits are disabled: [index: -1, cluster: -1] <= 0)][YES(allocation awareness is not enabled, set cluster setting [cluster.routing.allocation.awareness.attributes] to enable it)][YES(index has a preference for tiers [data_content] and node has tier [data_content])][YES(shard is not a follower and is not under the purview of this decider)][YES(decider only applicable for indices backed by searchable snapshots)][YES(this decider only applies to indices backed by searchable snapshots)][YES(decider only applicable for indices backed by searchable snapshots)][YES(this node's data roles are not exactly [data_frozen] so it is not a dedicated frozen node)]"
}
],
"type": "illegal_argument_exception",
"reason": "[move_allocation] can't move 1, from {elasticsearch3}{T-R4unaNTrS3cG0TBLZI1w}{VnPxLF9MSSyY2i5v28y34w}{172.21.0.4}{172.21.0.4:9300}{cdfhilmrstw}{ml.machine_memory=8232894464, xpack.installed=true, transform.node=true, ml.max_open_jobs=512, ml.max_jvm_size=536870912}, to {elasticsearch2}{fZmPapXcTmOXUZW5qgY37g}{5BmI1q8hS8SBr6Pn7itftw}{172.21.0.3}{172.21.0.3:9300}{cdfhilmrstw}{ml.machine_memory=8232894464, ml.max_open_jobs=512, xpack.installed=true, ml.max_jvm_size=536870912, transform.node=true}, since its not allowed, reason: [YES(shard has no previous failures)][YES(shard is primary and can be allocated)][YES(explicitly ignoring any disabling of allocation due to manual allocation commands via the reroute API)][YES(can relocate primary shard from a node with version [7.17.5] to a node with equal-or-newer version [7.17.5])][YES(no snapshots are currently running)][YES(ignored as shard is not being recovered from a snapshot)][YES(this node is not currently shutting down)][YES(neither the source nor target node are part of an ongoing node replacement (no replacements))][YES(node passes include/exclude/require filters)][NO(a copy of this shard is already allocated to this node [[wedul2][1], node[fZmPapXcTmOXUZW5qgY37g], [R], s[STARTED], a[id=YXQNS0DQTbqQ0yAh6AtE7Q]])][YES(enough disk for shard on node, free: [49.3gb], shard size: [3.3kb], free after allocating shard: [49.3gb])][YES(below shard recovery limit of outgoing: [0 < 2] incoming: [0 < 2])][YES(total shard limits are disabled: [index: -1, cluster: -1] <= 0)][YES(allocation awareness is not enabled, set cluster setting [cluster.routing.allocation.awareness.attributes] to enable it)][YES(index has a preference for tiers [data_content] and node has tier [data_content])][YES(shard is not a follower and is not under the purview of this decider)][YES(decider only applicable for indices backed by searchable snapshots)][YES(this decider only applies to indices backed by searchable snapshots)][YES(decider only applicable for indices backed by searchable snapshots)][YES(this node's data roles are not exactly [data_frozen] so it is not a dedicated frozen node)]"
},
"status": 400
}
a copy of this shard is already allocated to this node (주요원인)
- 옮기려고하는 node에 이미 replica shard가 존재하고 있어서 발생하는 에러로 위에 그림에서 보면 shard1에 replica shard가 이미 존재하는것을 확인할 수 있다.
total shard limits are disabled
- total shard가 제한이 있을 경우 문제인데 disabled되어있어서 이유가 아니다.
enough disk for shard on node
- 대상 노드에 shard를 할당하기에 충분한 디스크 공간이 있는 것으로 보여서 이유가 아니다.
shard is not a follower and is not under the purview of this decider
allocation awareness is not enabled
this node's data roles are not exactly [data_frozen] so it is not a dedicated frozen node
- 여러 힌트들을 확인해 볼 수 있다.
그럼 위에서 주요이슈가 되었던 동일한 shard가 없는 elasticsearch1 노드로 옮겨보자.
POST /_cluster/reroute
{
"commands": [
{
"move": {
"index": "wedul2",
"shard": 1,
"from_node": "elasticsearch3",
"to_node": "elasticsearch1"
}
}
]
}
잘 옮겨진다.
모든 노드의 replica shard가 있는 상태에서 primary shard를 노드를 이동하고 싶을 때
노드가 자주 교체되고 몇개의 노드가 shutdown되면서 데이터가 유실될 수 있는 환경에서는 모든 노드에 replica를 넣기도한다. 보통이럴때는 auto_expand_replicas: "0-all"로 설정하여 진행한다.

모든 primary shard가 elasticsearch4노드에 모여있으서 이것을 elasitcsearch5, elasitcsearch6 node에 옮겨보겠다.
이때는 모든 샤드가 노드에 다있어서 위에서 발생했던 동일 replica shard, primary shard가 이동하려는 곳에 같이있어서 발생했던 이슈가 무조건 발생한다. (a copy of this shard is already allocated to this node)
그래서 cancel을 사용해서 primary shard 할당을 cancel해주면 replica shard에 primary shard가 할당되면서 primary shard를 분산할 수 있다.
POST localhost:19200/_cluster/reroute
{
"commands": [
{
"cancel": {
"index": "wedul",
"shard": 3,
"node": "elasticsearch6",
"allow_primary": "true"
}
}
]
}
근데 이렇게 하면 특정 노드에 할당할수 없고 마지막에 올라온 노드로 자동으로 primary shard가 할당된다.
내가 찾은 방법은 우선 auto_expand_replica 옵션을 false로 끄고 number_of_replicas의 값을 0으로 바꾸면 replica shard는 모두 사라지고 primary shard는 각 노드에 분산되어 저장된다.

PUT localhost:19200/wedul/_settings
{
"settings": {
"number_of_replicas": 0,
"auto_expand_replicas": false
}
}
primary shard가 분산된걸 확인할 수 있다. 그다음 다시 auto_expand_replicas옵션을 "0-all"로 켜주면 이상태에서 replica shard만 붙는다.

replica shard는 조회 성능에 많은 영향을 끼치고 이과정에서 만약 노드하나가 죽어서 primary shard가 날아간다면... 조심해야한다. 오히려 reindex를 해주는게 나을수도 있지만 운영중인환경에서 쉽지 않은 선택이다.
관련해서 elasticsearch github에도 issue ticket이 올라와 있으나 아직 뾰족하게 어떻게 하는게 좋을지 감이 오지는 않는다. index를 하나 더만들고 alias를 같이 붙이고 reindex를 하면서 is_write_true를 새로운 index에 붙여야하나.. 질문을 올려보긴 했는데 기다려보자.
주의사항
Shard rerouting은 Elasticsearch 클러스터의 샤드를 다시 할당하는 작업을 의미합니다. 이 작업은 특정 상황에서 유용할 수 있지만, 잘못 사용하거나 신중하지 않게 진행할 경우 몇 가지 위험성이 있다. 아래는 Shard reroute 작업의 위험성에 대한 몇 가지 주요 요인들이다.
1. 데이터 손실
Shard rerouting은 샤드를 다른 노드로 이동시키는 작업이므로 실수로 잘못된 노드로 샤드를 이동시키면 해당 샤드에 저장된 데이터를 손실할 수 있다. 신중하게 계획되지 않은 샤드 이동은 데이터 유실을 초래할 수 있으므로 조심해야 한다.
2. 클러스터 불안정성
Shard reroute 작업은 클러스터의 상태를 변경하는 작업이기 때문에 클러스터 불안정성을 유발할 수 있다. 잘못된 샤드 이동이나 충돌하거나 네트워크 문제가 발생하면 클러스터의 안정성과 가용성이 저하될 수 있다.
- 다행히 primary shard 이동 시 기존 primary shard는 유지한채 새로운 shard를 복사하면서 switch하기 때문에 이것만으로는 cluster가 red가 되지 않는다. 단, 진행하는 도중에 여러이유로 발생할수 있으니 신중히 테스트가 필요하다.

3. 네트워크 부하
Shard reroute 작업은 노드 간에 샤드 데이터를 이동시키므로 클러스터의 네트워크 부하가 증가할 수 있다. 대규모 클러스터에서 많은 샤드를 이동시키는 경우 네트워크 병목 현상이 발생할 수 있으므로 성능을 감안하여 계획해야 한다.
4. 클러스터 성능 저하
Shard reroute 작업은 클러스터의 상태를 변경하므로 이 작업이 실행되는 동안에는 클러스터 성능이 저하될 수 있다. 특히, 대규모 클러스터에서 수천 개의 샤드를 이동시키는 경우 클러스터의 응답 속도가 느려질 수 있다.
5. 충돌 위험
병렬로 실행되는 shard reroute 작업이 충돌하거나 동시에 여러 작업이 발생할 경우 예상치 못한 결과가 발생할 수 있다. 이러한 충돌은 클러스터의 안정성을 악화시킬 수 있으므로 주의가 필요하다.
위험성을 최소화하려면 Shard reroute 작업을 신중하게 계획하고 테스트를 거쳐야 한다. 큰 변화를 가하는 작업이므로 라이브 환경에서 수행하기 전에 백업을 만들고 롤백 계획을 갖추는 것이 좋다. 또한 Elasticsearch 클러스터의 상태와 성능을 모니터링하고 작업 진행 중에 잠재적인 문제를 신속하게 식별하고 대응해야 한다.
#부록
사용한 클러스터 docker-compose.yml 정보
version: "2"
services:
elasticsearch1:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.5
container_name: elasticsearch1
environment:
- cluster.name=docker-cluster
- node.name=elasticsearch1
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- indices.lifecycle.history_index_enabled=false
- xpack.monitoring.collection.enabled=false
- discovery.seed_hosts=elasticsearch1,elasticsearch2,elasticsearch3
- cluster.initial_master_nodes=elasticsearch1,elasticsearch2,elasticsearch3
- xpack.security.enabled=false
- node.roles=master
ports:
- "19200:9200"
elasticsearch2:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.5
container_name: elasticsearch2
environment:
- cluster.name=docker-cluster
- node.name=elasticsearch2
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- xpack.monitoring.collection.enabled=false
- indices.lifecycle.history_index_enabled=false
- discovery.seed_hosts=elasticsearch1,elasticsearch2,elasticsearch3
- cluster.initial_master_nodes=elasticsearch1,elasticsearch2,elasticsearch3
- xpack.security.enabled=false
- node.roles=master
ports:
- "29200:9200"
elasticsearch3:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.5
container_name: elasticsearch3
environment:
- cluster.name=docker-cluster
- node.name=elasticsearch3
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- xpack.monitoring.collection.enabled=false
- indices.lifecycle.history_index_enabled=false
- discovery.seed_hosts=elasticsearch1,elasticsearch2,elasticsearch3
- cluster.initial_master_nodes=elasticsearch1,elasticsearch2,elasticsearch3
- xpack.security.enabled=false
- node.roles=master
ports:
- "39200:9200"
elasticsearch4:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.5
container_name: elasticsearch4
environment:
- cluster.name=docker-cluster
- node.name=elasticsearch4
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- xpack.monitoring.collection.enabled=false
- indices.lifecycle.history_index_enabled=false
- discovery.seed_hosts=elasticsearch1,elasticsearch2,elasticsearch3,elasticsearch4
- cluster.initial_master_nodes=elasticsearch1,elasticsearch2,elasticsearch3
- xpack.security.enabled=false
- node.roles=data
ports:
- "49200:9200"
'데이터베이스 > Elasticsearch' 카테고리의 다른 글
| elasticsearch routing 사용하기 (0) | 2023.07.25 |
|---|---|
| elasticsearch cluster 구성 시 기본으로 생성되는 index확인 (0) | 2023.07.25 |
| Line 세미나. 대규모 음악 데이터 검색 기능을 위한 Elasticsearch 구성 및 속도 개선 방법 - 2. 클러스터 튜닝 (0) | 2021.11.14 |
| Line 세미나. 대규모 음악 데이터 검색 기능을 위한 Elasticsearch 구성 및 속도 개선 방법 - 1. 검색 쿼리 개선 (0) | 2021.11.14 |
| Java Lowlevel client bulk api에서 filter_path 사용하기 (0) | 2021.07.26 |