
문제상황
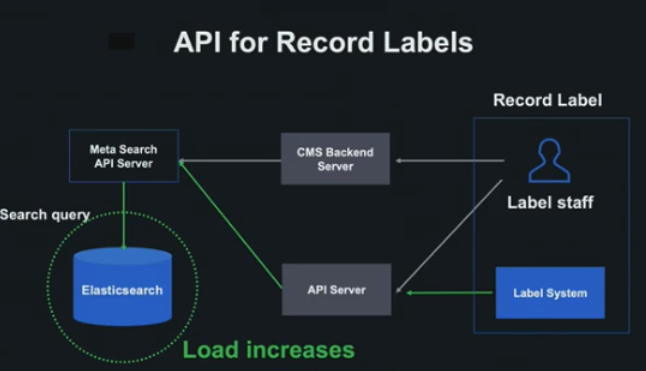
- cms 이외에도 외부에 api server를 열어서 데이터를 저장할 수 있도록 열어줬는데 데이터 부하가 되면서 elasticsearch에 부하가 오고 data node가 100프로 되는 등 문제가 발생된다.
- 처음에는 쿼리 튜닝등의 방식으로 문제를 해결하였으나 data node의 cpu가 100프로가 되는등의 문제가 계속 유지되었다.

- 데이터 노드를 늘림으로서 검색을 여러 서버로 분산하기 때문에 검색 속도를 늘릴 수 있었다. 하지만 비용이 너무 많이 들었다.
- 어느 회사든지 간에 끊임 없는 수평확장은 어렵다.
해결방안


- shard와 replica를 구성하여 부하를 여러 노드로 분산하고 가용성을 늘림


- shard와 replica는 일반적인 규칙이 없다.
- 상황에 따라 어떤 shard와 replica 구성이 좋은지는 꼭 테스트를 통해 해야하면 이곳에서는 shard 6, replica 1로 구성하여 문제를 해결 했다.
- 분리하고 보니 shard당 크기는 16GB 정도였다. (권고되는것도 shard당 20GB를 넘지 않도록 권고중)
나의 생각
- replica를 구성하여 가용성을 늘리고 검색 performance에 기여할 수 있다고 알고 있다. 하지만 replica를 늘려 각 노드의 샤드가 많아지는게 좋지 않을 수도 있다는 elasitcsearch 문서에 내용이 있다. (https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-search-speed.html#_replicas_might_help_with_throughput_but_not_always) 이처럼 replica가 검색 성능에 무조건 도움을 주는것이 아니기에 테스트가 꼭 필요하다.
- shard도 여러곳에 분산되어있으면 한쪽 노드에 집중되는 I/O등의 문제를 분산할 수 있지만 또 각각의 샤드의 검색결과를 모아야하기 때문에 그또한 cpu에게 일을 주는 부분도 있다. (인덱싱에는 확실히 성과가 있음)
- 결론은 답이 없다. 상황에 맞게 테스트하고 최적의 shard분배를 찾고 replica는 고가용성이 필요한 여부와 퍼포먼스등을 고려해서 진행한다. (이걸 나만 삽질하는게 아니군!)
'데이터베이스 > Elasticsearch' 카테고리의 다른 글
| shard reroute api 테스트 (0) | 2023.07.25 |
|---|---|
| elasticsearch cluster 구성 시 기본으로 생성되는 index확인 (0) | 2023.07.25 |
| Line 세미나. 대규모 음악 데이터 검색 기능을 위한 Elasticsearch 구성 및 속도 개선 방법 - 1. 검색 쿼리 개선 (0) | 2021.11.14 |
| Java Lowlevel client bulk api에서 filter_path 사용하기 (0) | 2021.07.26 |
| Bulk Index 진행 시 search api 느려지는 현상 해결 방법 리서치 (0) | 2021.07.24 |