sort
dynamoDbEnhancedClient에서 QueryConditional에서 sort key range 조회하기
아래와 같이 데이터가 존재하는 상황을 가정해보자. import lombok.Builder; import lombok.Getter; import lombok.NoArgsConstructor; import lombok.Setter; import software.amazon.awssdk.enhanced.dynamodb.mapper.annotations.DynamoDbBean; import software.amazon.awssdk.enhanced.dynamodb.mapper.annotations.DynamoDbPartitionKey; import software.amazon.awssdk.enhanced.dynamodb.mapper.annotations.DynamoDbSortKey; @Getter @Setter ..

RestHighLevelClient를 사용하여 search after 기능 구현하기
https://wedul.site/541에서 search after 기능을 사용해서 검색을 하는 이유를 알아봤었다. 그럼 spring boot에서 RestHighLevelClient를 이용해서 search after를 구현을 해보자. 1. Mapping 우선 index가 필요한데 간단하게 상품명과 지역 가격정보들을 가지고 있는 wedul_product 인덱스를 만들어 사용한다. { "settings": { "index": { "analysis": { "tokenizer": { "nori_user_dict": { "type": "nori_tokenizer", "decompound_mode": "mixed", "user_dictionary": "analysis/userdict_ko.txt" } }, "ana..

SELECT-LIST 컬럼 가공시 정렬연산 수행 확인 및 개선방법
인덱스가 Id, ch_date, ch_order 순으로 생성되어 있을 경우 MIN 값을 구해도 별도의 정렬연산을 수행하지 않는다. 수직적 탐색을 통해서 가장 왼쪽지점에서 보는 최소 값이 바로 구하고자 하는 값이기 때문이다. 1SELECT MIN(ch_date) FROM scott.SORT_TEST WHERE ID = ‘C’;csMAX의 경우도 마찬가지이다. MIN과 다른 점은 왼쪽에서 찾는게 아니라 가장 오른쪽에 있는 데이터를 찾는다는 점이다.1SELECT MAX(ch_date) FROM scott.SORT_TEST WHERE ID = ‘C’;cs 그래서 두 개의 실행계획을 살펴보면 인덱스 리프 블록의 왼쪽(MIN) 또는 오른쪽 (MAX)에서 레코드 하나(FIRST ROW)만 읽고 멈춘다.1SELECT ..

인덱스를 이용한 sort 연산 생략
인덱스 Range Scan이 가능하려면 가공하려는 컬럼의 데이터가 정렬되어 있어야 가능하다. 인덱스는 그렇기 때문에 정렬이 되어있다. 그래서 인덱스를 사용하는 이유가 있다. 테이블 생성1234create table sort_test (id char,ch_date date,ch_order varchar(10));cs 제약조건 추가1ALTER TABLE SCOTT.SORT_TEST ADD CONSTRAINT ODER_PRIMARY PRIMARY KEY (ID,CH_DATE,CH_ORDER);cs 데이터 실행계획PK를 기준으로 알아서 정렬이 되어있다. ( ID -> CH_DATE -> CH_ORDER 순서대로) 만약 별도로 order by를 sql에 지정한다고 해도 옵티마이저는 sort order by를 진행..
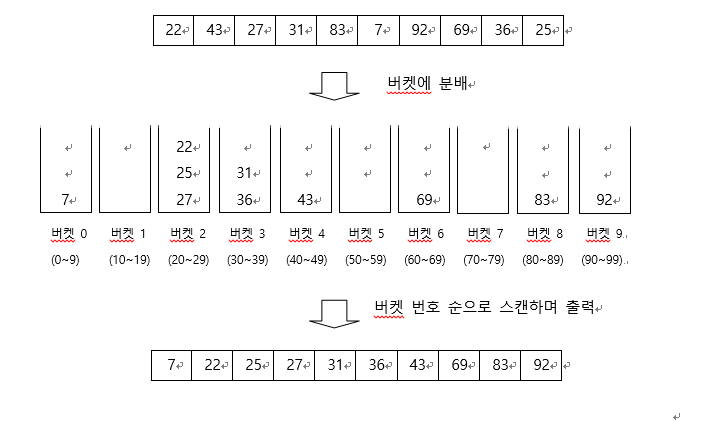
Deque를 통해 버킷정렬(Bucket Sort)을 해보자.
저번시간에 만들었던 Deque를 사용하여 버킷정렬을 연습해보기로 했다. 우선 버킷정렬이 무엇인지 알아보자. 버킷정렬(Bucket Sort) 이란?? n개의 데이터를 정렬할 때 같은 크기의 간격을 갖는 n개의 버켓에 데이터를 분배한다. 입력 데이터가 균일하게 분포되었다면 각 버켓에는 1개의 데이터가 있게 되지만, 균일하게 분포되지 않으면 다수의 데이터가 버켓에 들어 갈 수 있으며 각 버켓의 데이터는 정렬하여 저장한다. n개의 모든 데이터를 버켓에 분배하였다면 버켓 번호 순으로 스캔하여 출력하면 정렬된 데이터를 얻게 된다. [예제] 최대 2자리를 갖는 정수 (0부터 99까지의 정수) 10개를 버켓 정렬한다고 하자. 각 버켓은 같은 크기의 간격 (0-9, 10-19, 20-29,…, 90-99)을 갖는 10개..
정렬알고리즘 - 버블정렬
1234567891011121314151617for(int i = money.length; i>0; i--){ for(int j=0;jmoney[j+1]){ temp=money[j]; money[j]=money[j+1]; money[j+1]=temp; } } }Colored by Color Scriptercs