Queue

Redis에서 Pub/Sub 방식 소개 및 Spring Boot에서 구현해보기
redis에 추가된 SUBSCRIBE, UNSUBSCRIBE 그리고 PUBLISH는 Publish/Subscribe 메시지 패러다임을 구현한 기능이다. sender(publisher)들은 특별한 receiver(subscriber)에게 값을 전달하는게 아니라 해당 채널에 메시지를 전달하면 그 메시지를 구독하고 있는 subscribe에게 메시지를 전송한다. subscribers는 하나 또는 그 이상의 채널에 구독을 요청하고 publisher가 누구인지 상관 없이 해당 채널에 들어온 모든 메시지를 읽게된다. 이 subscriber와 publisher의 decoupling은 확장성있는 성장을 가져올 수 있다. Redis-Cli로 기능 사용하기 subscriber redis-cli를 열고 SUBSCRIBE 채널..
![[번역] shared message queues와 publish-subscribe 방식에 Custom Group 방식을 더한 Kafka 소개](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F99872E465C64B57028)
[번역] shared message queues와 publish-subscribe 방식에 Custom Group 방식을 더한 Kafka 소개
전통적으로 메시지 모델은 Shared Message Queue, Publish-subscribe로 구분된다. 두 가지 모델 모두 그들만에 pros and cons를 보유하고 있다. 하지만 이 두개의 모두 최초 디자인 제한 때문에 큰 데이터를 다루기에는 부족했다. Apache Kafka는 두 모델 중 publish-subscribe 메시징 모델을 구현한 모델로 부족했던 부분을 수정하고 실시간 분석을 위한 스트리밍 데이터를 처리할 수 있도록 가능해졌다. kafka는 LinkedIn에서 2010년에 방대한 데이터 처리를 위해서 개발되었다. Apache Kafka는 전통적인 메시징 모델이 달성하지 못한 격차를 해소했다. Kafka는 두 모델의 개념을 구현하여 단점을 극복하고 동시에 두 가지 방법론을 모두 통합 ..

Kafka 요약 정리
Topic- 메시지는 Topic에 분류된다. Partition- Topic은 partition으로 구분된다.- 파티션에 쌓이는 데이터는 로그라고 부르고 각 파티션에 나눠서 저장된다. Topic이 파티션으로 나뉘는 이유- Topic 내부에 파티션이 없을경우 메시지를 보내는 대상이 많아질경우 append 속도가 버거워진다. - 병렬로 분산저장하고자 Partition 개념 생성- 한번 생성한 파티션은 운영중에 줄일 수 없기 때문에 설계시 조심 Consumer- Topic에 있는 데이터를 읽는 대상 Consumer Group- Consumer를 여러개 묶어놓은 것. Consumer Group이 필요한 이유.- 소비를 진행 하던 Consumer가 죽어버릴 경우를 Rebalance 상황이라고 하는데 이럴경우 파티션..

Kafka 정리
카프카는 분산형 스트리밍 플랫폼으로써 다음으로 정의할 수 있다. 메시지 큐와 유사하게 스트림을 publish하고 subscribe 하는 방식이다.fault-tolerant 지속 방식으로 레코드들의 스트림들을 저장한다. 용도 시스템이나 어플리케이션에서 발생한 실시간 스트리밍 데이터를 안정적으로 데이터 파이라인 구축할 때데이터 스트림을 전송하거나 처리해야할 때 사용 구성 하나이상에 서버에 여러 cluster로 구성되어 있다.topic이라는 카테고리로 레코드 스트림들을 저장한다.각각의 레코드들은 key, value, timestamp로 구성되어 있다. 핵심 APIProducer API하나 또는 그 이상의 카프카 topic을 데이터 스트림에 발행할 수 있도록 해주는 APIConsumer API어플리케이션이 하나..
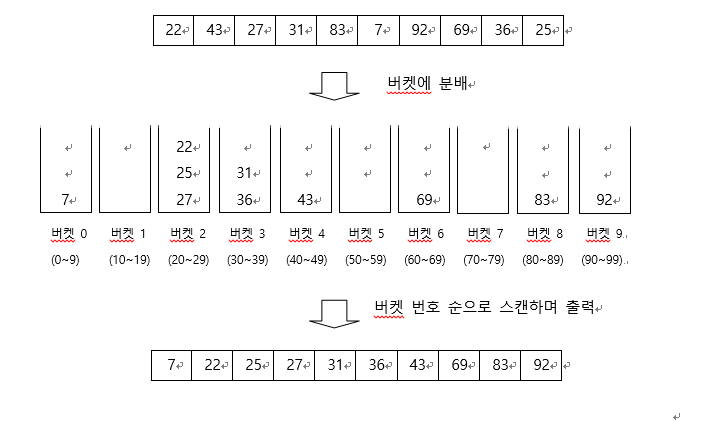
Deque를 통해 버킷정렬(Bucket Sort)을 해보자.
저번시간에 만들었던 Deque를 사용하여 버킷정렬을 연습해보기로 했다. 우선 버킷정렬이 무엇인지 알아보자. 버킷정렬(Bucket Sort) 이란?? n개의 데이터를 정렬할 때 같은 크기의 간격을 갖는 n개의 버켓에 데이터를 분배한다. 입력 데이터가 균일하게 분포되었다면 각 버켓에는 1개의 데이터가 있게 되지만, 균일하게 분포되지 않으면 다수의 데이터가 버켓에 들어 갈 수 있으며 각 버켓의 데이터는 정렬하여 저장한다. n개의 모든 데이터를 버켓에 분배하였다면 버켓 번호 순으로 스캔하여 출력하면 정렬된 데이터를 얻게 된다. [예제] 최대 2자리를 갖는 정수 (0부터 99까지의 정수) 10개를 버켓 정렬한다고 하자. 각 버켓은 같은 크기의 간격 (0-9, 10-19, 20-29,…, 90-99)을 갖는 10개..
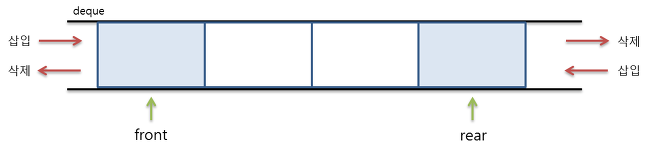
Deque를 직접 구현해보기
큐는 삽입과 삭제가 리스트의 한쪽 방향에서만 이루어지지만 deque는 리스트의 양쪽 끝 모두에서 이루어질 수 있다. 따라서 양쪽 방향 모두 삽입과 삭제가 이루어질 수 있으므로 기존의 큐나 스택으로 사용할 수 있어 유연하게 사용할 수 있다. 사진출처 : https://dh00023.github.io/algorithm/ds/2018/04/25/algorithm-10/ 이런 Deque를 직접 구현해 보자. 우선 Deque의 기능을 정리한 인터페이스이다.1234567891011121314151617181920212223package practice3; public interface Deque { public void addFirst(T item); public void addLast(T item); public..

Javascript 처리과정
javascript의 처리과정 순서에 대해서 알아보자. 브라우저에서 이벤트가 발생하면 Event Queue에 삽입해 놓고 이를 stack이 비어지면 Event Queue에서 작업이 있는지 확인한다. 그리고 작업이 있는 경우 그것을 꺼내서 사용한다. [작업순서](1) 이벤트 큐에 작업이 있는지 확인한다. (2) 스택이 비었을 때 큐에 있는 작업을 꺼내 수행한다.