Mapping
[번역] 2-2. Domain 모델 (Enum, UUID, Date, Attribute, Generated Properties)
2.3.7 Enums 매핑 Hibernate는 기본값 유형으로써 다양한 방법으로 Java Enum의 매핑을 지원한다. @Enumrated 기본적인 JPAdml enums의 매핑 방법은 @Enumrated 또는 @MapKeyEnumrated 애노테이션을 통해 javax.persistence.EnumType에 표시된 두 가지 전략 중 하나에 따라 enum 값이 저장된다는 원칙에 따라 동작한다. ORDINAL - java.lang.Enum#ordinal에 기재된대로 Enum 클래스 내에서 Enum값의 순서에 따라 저장된다 STRING - java.lang.Enum#name 방식에 기재에 따라 Enum값의 이름에 따라서 저장된다. 아래 예시로 PhoneType이라는 Enum이 있다고 가정해보자. public e..

Elasticsearch reindex시 alias를 사용하여 무중단으로 진행하기 & big index 리인덱싱 시 비동기 처리 방법
Elasticsearch reindex를 진행할 때, 단순하게 새로운 인덱스를 만들고 reindex api를 진행하고 기존 인덱스를 지우고 새로 만들어서 다시 reindex를 해줬다. (이전글: https://wedul.site/611?category=680504) 하지만 그것은 해당 인덱스의 document의 수가 적어서 금방 진행이 되었었고 만약 document수가 10만가지만 넘어도 생각보다 오래걸려서 서비스의 흐름이 끊어지게 된다는걸 인지하지 못했다. 같은 회사 동료분께서 해당 부분에 대해서 말씀해주셨고, 그 분이 가이드 해주신대로 진행해서 reindex를 무중단하게 진행하는 방법을 찾아봤다. Alias를 이용하여 reindex하기 기존 index wedul의 매핑구조이다. PUT wedul { ..
[번역] Elasticsearch 퍼포먼스 튜닝 방법 - ebay
Elasticsearch에 대해 검색하다가 ebay에 퍼포먼스 튜닝방법에 대해 좋은 글이 있어서 간단하게 정리해봤다. 새롭게 알게된 사실이 많아서 좋았다. 정리 잘된 기술 블로그를 보는것은 책을 읽는거보다 훨씬 유익한 경우가 많은 것 같다. Elasticsearch 엘라스틱 서치는 아파치 루씬을 기반으로한 검색과 분석 엔진으로 데이터를 실시간에 가깝게 보여주고 분석해 준다. 실시간성으로 분석과 검색을 위해서 많이 사용되는 엘라스틱 서치의 퍼포먼스는 무엇보다 중요한데 이를 위한 퍼포먼스 튜닝방법을 정리해보자. 높은 엘라스틱서치의 퍼포먼스를 위해서는 많은 처리량, 낮은 검색 지연시간등이 요구된다. 고효율성 Elasticsearch를 위한 솔루션 - 효율 적인 인덱스 디자인 인덱스를 설계하다보면 하나의 인덱스..
Elasticsearch에서 reindex를 이용해서 매핑정보 변경하기
Elasticsearch에서 index를 구성하다보면 매핑정보를 추가하거나 수정하고 싶을때가 있다. 내가 아는 내에서는 한번 생성된 index의 매핑정보를 변경하는건 어렵다. 그래서 reindex를 통해 index의 매핑정보를 변경해줘야한다. 우선 wedul_mapping이라는 인덱스가 있다고 해보자. 매핑 정보는 다음과 같다. PUT wedul_mapping { "mappings": { "_doc": { "dynamic": "false", "properties": { "id": { "type": "integer" }, "name": { "type": "text", "fields": { "keyword": { "type": "keyword" } } } } } } } 이때 name에서 keyword필드를 ..

elasticsearch 7.0 docker 설치 후 변경사항 확인
엘라스틱서치 7.0이 출시했다. 엘라스틱서치 7.0에는 kibana UI변경과 multi mapping type 제거 등의 이슈가 있다. 우선 달라진점을 확인하기 위해 docker에 설치해보자. 설치 elasticsearch docker run --name elastic7.0 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.0.0 kibana docker run -d --rm --link elastic7.0:elastic-url -e "ELASTICSEARCH_HOSTS=http://elastic-url:9200" -p 5601:5601 --name kibana7...
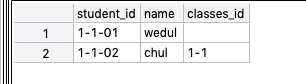
연관관계 매핑 - 다대일 매핑 (단반향)
연관관계 매핑을 해야하는 경우가 많다. 예를 들어 학생을 가지고 학생에 소속 반을 찾거나 반을 사용해서 학생들을 찾거나 할 때가 있다. 이 때 양방향과 단방향 관계가 존재하는데 아래의 객체 형태를 보면 이해가 더 쉽다. 단방향 class Student { Class class; } class Class {} 양방향 class Student { Class class; } class Class { Student student; } 이중에서 먼저 단방향 연관 관계에 대해 먼저 공부해보자. 단방향 연관관계 학생과 반이있다. 학생은 하나의 반에 소속된다. 학생과 반은 다대일 관계이다. (학생이 다, 반이 일) 학생 테이블을 담는 객체는 Student, 반 테이블을 담는 객체는 Classes를 사용한다. 학생 테이..
/과 /*의 차이점을 포함한 url-mapping 정리
web.xml에서 servlet-mapping 설정 시 url-pattern을 설정하는 것에 대해 정확한 정리가 되어 있지 않아서 정리해보았다. [url-pattern별 의미] 1. "/"로 시작하고 "/*"로 끝나는 패턴은 path로 인식 -> /wedul/list, /wedul/user 등 모든 URL 패턴을 매칭 2. "*."으로 시작하는 경우 확장자 매칭 -> 과거 확장자 *.do 또는 *.ajax와 같은 패턴 매칭 3. "/"만 정의한 경우 디폴트 서블릿 의미 -> default servlet은 servlet mapping에 걸리지 않은 나머지 매핑요소들을 처리한다. 4. 그 외의 경우는 정확하게 일치하는 매칭 /* Dispathcher servlet을 /*으로 했을때의 문제/*으로 매핑하였을 ..