필터
Elasticsearch nori 형태소 분석기에서 readingform filter를 이용해서 한자 내용을 한글로 변환하기
Elasticsearch filter에서 한자로 검색했을 때 일치하는 한글 결과로 tokenizing하게 해주는 filter가 있다. 해당 filter는 nori-readingform이다. 적용 방법은 기존에 synonmys나 speech필터 적용과 동일하다. 인덱스 생성 위에서 부터 사용했던 인덱스에 nori_readingform 필터를 추가해서 생성만 해주면 된다. PUT wedul_anaylyzer { "settings": { "index" : { "analysis" : { "tokenizer": { "nori_user_dict": { "type": "nori_tokenizer", "decompound_mode": "none", "user_dictionary": "dic/nori_userdict_k..
Elasticsearch 특정 형태소 종류를 제외하여 검색하는 필터 nori_part_of_speech 적용
Elasticsearch를 사용하여 analyze를 사용하다가 조사, 형용사 등등을 제외하고 형태소 토크나이즈가 되어야 했다. 그래서 정식 문서를 찾아보더니 nori_part_of_speech라는 필터가 있었다. 우선 저번 시간에 만들었던 wedul_analyzer 인덱스를 이용해서 토크나이즈를 해보자. { "tokens": [ { "token": "바보", "start_offset": 0, "end_offset": 2, "type": "word", "position": 0 }, { "token": "위들", "start_offset": 3, "end_offset": 5, "type": "word", "position": 1 }, { "token": "이", "start_offset": 5, "end_o..
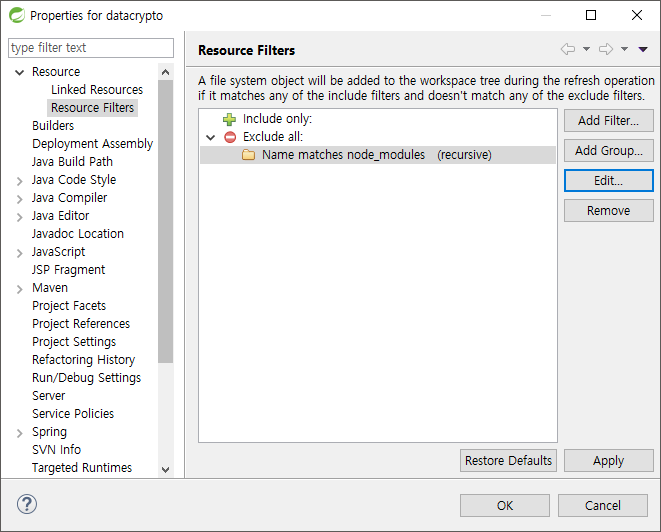
Spring에서 node_modules 하위 폴더 까지 모두 보이지 않도록 filter 설정하기
npm을 사용하면 다운받은 모듈들이 저장되는 node_modules가 이클립스에 출력되어 에러를 출력할 때가 있다. 이 부분은 커밋을 하거나 할때도 자꾸 보여서 귀찮은데 이를 보이지 않도록 설정하는 방법을 알아보자. 우선 STS에서 해당 프로젝트의 우측클릭을 하여 propertes에 접속한다.그 후 Edit Filter 를 눌러서 규칙을 등록해야 한다. 규칙은 Filter Type은 Exclude all 을 선택하고, 모든 하위의 폴더들까지 적용되도록 설정하고Filter Details에 node_modules를 입력해준다. 이렇게 설정을 진행하고 나면 이클립스 프로젝트 트리에서 node_modules가 사라진것을 확인할 수 있다.