차이
Spring reactor Mono와 Flux 정리
지금까지 Spring5에서 추가되었던 리액트 프로그램을 사용하여 간단한 프로그램을 만들어 봤지만 정확하게 Mono와 Flux에 차이와 정의를 정리하지 못한 것 같다. 이번기회에 두 개의 정확한 차이와 사용방법등을 정리해보자. 리액티브 프로그래밍 비동기 블록킹 프로세스로 동작하는 애플리케이션을 논블록킹 프로세스로 동작하기 위해서 지원하는 프로그래밍. (현재 node.js의 동작방식과 유사) 기존 Spring 블록킹 방식 웹에서 서버에 요청이 왔을때 서버는 요청에 대한 적절한 응답을 보내야 하는데 만약 작업이 오래 걸릴 경우에는 요청에 대한 응답이 모두 종료될 때까지 블록킹된다. Spring에서는 그래서 동시 요청 처리를 위해서 멀티 thread를 지원한다. 그러면 하나의 작업이 thread에서 진행되고 다..

Mysql Exists와 IN절 설명과 차이점
두 개 모두 where절에 조건을 보고 결과를 걸러낼때 사용하는데 정리가 잘 안되서 정리해봤다. Exists 서브쿼리가 반화나는 결과값이 있는지를 조사한다. 단지 반환된 행이 있는지 없는지만 보고 값이 있으면 참 없으면 거짓을 반환한다.1SELECT * FROM sample1;cs1SELECT * FROM sample2;cs 두 개의 테이블중 조건에 맞는 Row만 추출된다. 1SELECT * FROM sample1 s1 WHERE EXISTS(SELECT * FROM sample2 s2 WHERE s1.no = s2.no);cs그럼 반대로 조건에 맞지 않는 ROW만 추출하고 싶으면 어떻게 해야할까?1SELECT * FROM sample1 s1 WHERE NOT EXISTS(SELECT * FROM sam..
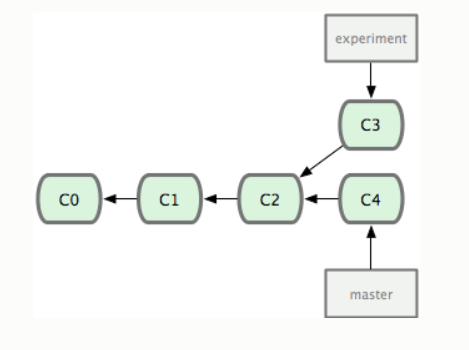
Git의 rebase를 이용한 커밋 정리 (merge와 차이)
Git을 처음 입사 후 진행했던 프로젝트에서 Gitlab을 통해 처음 접해보았다. 확실히 저장소 관리하는 방식과 커밋 전 단계가 제공되는 것 등등 편한 것이 많았다. 하지만 그 때 당시 딱히 팀원이 없었기에 히스토리 관리 및 flow 관리를 해야한다는 필요성을 알지도 못했고 듣지도 못했었다. 그러나 공부를 진행해보면서 git에 rebase라는 좋은 기능이 있다는 것을 알게되었고 배워보고 싶어 nhnent에서 제공하는 사내 교육에 참여하였다. 우선 첫 번째 글로 rebase와 merge에 차이를 설명하고 rebase를 진행해보자. rebase란? 우선 rebase는 base를 다시 지정한다 (re-base)의 의미이다. base가 무엇인가? 다음 그림을 보자. 그림을 보면 master의 c4와 experi..
JQuery함수의 append와 appendTo 차이
하나의 dom 객체를 다른 dom에 붙히려고 할때 JQuery에서 제공하는 append나 appendTo를 사용한다. 그런데 append와 appendTo가 헷갈리는 경우가 있는데 이 두개의 차이를 알아보자. 두 개 메서드의 결정적인 차이는 붙는 대상이 무엇이냐에 있다.아래 예제를 살펴보자123456 $('').appendTo($('#test'));$('#test').append($(''));cs 코드를 보면 두 개의 결과는 동일하다. 짐작하겠지만 appendTo는 뒤에있는 객체에 앞에있는 내용을 붙히겠다는 의미이고 append는 앞에있는 객체에 뒤라는 객체를 붙히겠다는 뜻이다. 영어 뜻을 잘 해석해서 진행하면 이해하기가 더 쉬울 것 같다.
Java List 인터페이스 중 CopyOnWriteArrayList 소개
자바에는 크게 4개의 List 인터페이스를 구현한 클래스가 있다. - Vector, ArrayList, LinkedList, CopyOnWriteArrayList 그 중 가장 생소한 이름이 있는데 CopyOnWriteArrayList이다. CopyOnWriteArrayList는 그냥 ArrayList랑 다르길래 화려한 이름을 가지고 있는걸까? ArrayList vs CopyOnWriteArrayList 일반 ArrayList의 경우 스레드에 안전하게 설게되어 있지 않기때문에 만약 스레드 처리가 필요한 List의 경우에 Vector를 사용하거나 ArrayList에 synchroized를 사용하여 처리하였다. 하지만 자바 1.5부터 있던 CopyOnWriteArrayList를 쉽게 이문제를 해결할 수 있다...