자바

모던 자바 인 액션 내용 정리
포킹 자바 8에서 추가된 스트림 api에서 데이터를 필터링, 추출, 그룹화 등의 기능을 진행할 수 있다. 이러한 동작들을 병렬화 할 수 있어 여러 cpu에서 작업을 분산해서 처리할 수 있다. 이런 작업을 포킹 단계라고 한다. 함수형 인터페이스 - 하나의 추상메서드를 가지고 있는 함수형 인터페이스지만 상속을 받은 인터페이스는 추상메서드를 하나만 가지고 있다고 하여도 함수형 인터페이스가 아니다. - 디폴트 메소드가 아무리 많아도 추상 메소드가 하나이면 함수형 인터페이스이다. - @FunctionalInterfeace 애노테이션을 붙이면 함수형 인터페이스가 아닌 경우 컴파일 에러를 발생 시킬 수 있다. 람다에서 지역변수를 final로 제약하는 이유 람다에서 지역변수가 final로 사용되는지 궁금한데 이는 인터..
백준 4673번 셀프 넘버
1 ~ 10000까지의 숫자중에 셀프 넘버가 아닌 데이터를 noSelfNumber에 집어넣고 loop를 순회하면서 selfNumber 여부를 체크하면 된다. 간단한 문제이다. https://www.acmicpc.net/problem/4673 4673번: 셀프 넘버 문제 셀프 넘버는 1949년 인도 수학자 D.R. Kaprekar가 이름 붙였다. 양의 정수 n에 대해서 d(n)을 n과 n의 각 자리수를 더하는 함수라고 정의하자. 예를 들어, d(75) = 75+7+5 = 87이다. 양의 정수 n이 주어졌을 때, 이 수를 시작해서 n, d(n), d(d(n)), d(d(d(n))), ...과 같은 무한 수열을 만들 수 있다. 예를 들어, 33으로 시작한다면 다음 수는 33 + 3 + 3 = 39이고, 그 다..
JPA 상속관계 매핑 전략
객체 지향으로 데이터베이스 중심 매핑을 변경하기 위해서 가장 애매한게 상속이다. 이런 상속관계속에서 테이블로 구현할 때 3가지 방법을 선택할 수 있다. 1) 각각의 테이블로 변환 : 각각을 모두 테이블로 만들고 조회할 때 조인을 사용. 2) 통합 테이블로 변환 : 테이블을 하나만 사용해서 통합 3) 서브타입 테이블로 변환 : 서브 타입마다 하나의 테이블을 만드는 방식. 순서대로 하나씩 정리해보자. ㅁ 각각의 테이블로 변환 (조인전략) - 부모와 각각의 자식 엔티티를 모두 각자의 테이블로 만들고 부모의 기본키와 자식의 외래키를 사용하여 조인하여 사용한다. - 자식 엔티티의 타입을 구별하기 위한 DTYPE 컬럼을 구분컬럼으로 추가하여 사용한다. (없어도 무관) 1234567891011121314@Entity..
JPA 매핑 어노테이션 - DDL
JPA 매핑에 사용되는 어노테이션은 크게 유형에 따라 4가지로 나누어진다.유형어노테이션객체와 테이블 매핑@Entity, @Table 기본 키 매핑@Id필드와 컬럼 매핑@Column연관관계 매핑@ManyToOne, @JoinColumn @EntityJPA를 사용해서 테이블과 매핑할 클래스에는 무조건 붙혀야하는 어노테이션이다. 속성으로 name을 지정할 수 있다. 안할 시 기본 클래스 이름으로 한다.1@Entity(name = "Member")cs - 기본 생성자가 필수로 있어야 한다. - final 클래스와 private 생성자는 할 수 없다. @Table엔티티와 매핑할 테이블을 지정한다. 생략하면 매핑하는 엔티티이름으로 대신한다. -name, catalog, schema, uniqueConstraints..
JPA 기본 어노테이션 설명
JPA에서 사용되는 기본적인 어노테이션 몇개를 정리해보자. @Entity- 클래스와 테이블과 매핑한다고 JPA에게 알려준다. 이렇게 @Entity가 사용될 클래스를 엔티티 클래스라고 한다. @Table- 엔티티 클래스에 매핑할 테이블 정보를 알려준다. (이 어노테이션을 생략하면 클래스 이름을 테이블정보로 매핑한다.) @Id- 엔티티 클래스의 필드를 테이블에 기본키로 매핑한다. (데이터베이스는 엔티티를 구별할때 이 키값으로 구분한다.) @Column- 필드를 컬럼에 매핑한다. 매핑 정보가 없는 필드- @Column을 생략하면 필드명을 사용해서 컬럼명과 매핑하게 된다. 만약 대소문자를 데이터베이스가 구분할 경우에는 꼭 위에 @Column어노테이션을 사용해서 진행해야한다. #Dialect(방언)- 데이터베이스..

백준 1929번 소수 구하기 문제
일반적으로 소수 구하는 방식으로 진행하면 시간이 너무 걸려서 에러가 발생한다. 그래서 고민하던 중에이런 생각이 났다. 모든 수는 자신의 제곱근 이상의 수로 나눠지지 않기 때문에 자신의 제곱근까지 2이상의 자연수로 나눠지는지 판단하면 된다고 생각했다. 그 결과 된다.1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556import java.math.BigDecimal;import java.util.ArrayList;import java.util.List;import java.util.Scanner; public class Main { public static void main(..
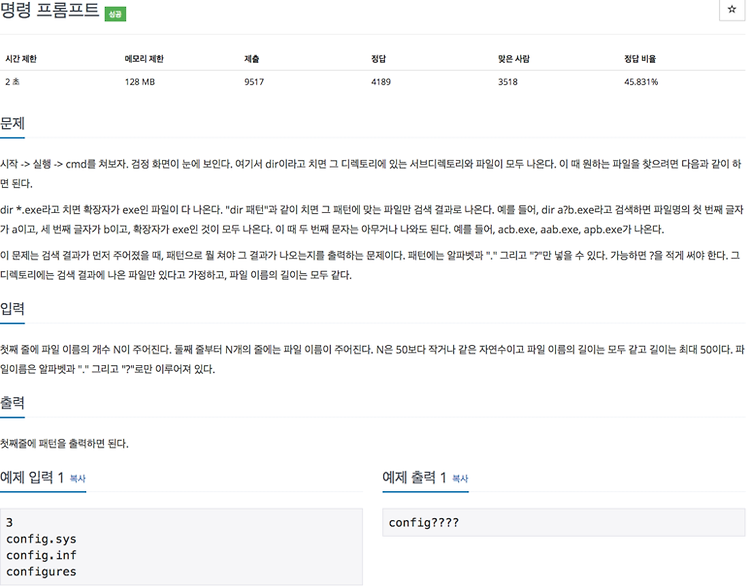
백준 알고리즘1032 명령프롬프트 문제
문제입력된 파일 리스트를 보고 공통적으로 사용될 수 있는 Regex를 찾아서 출력하는 문제이다. 코드 코드는 간단하게 처음입력받은 파일명을 기준으로 잡고 추가로 들어오는 나머지 파일명들과 다른 부분에 대해서 모두 ?로 바꿔버렸다. 12345678910111213141516171819202122232425262728293031323334353637import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 파일 개수 입력 int wordCnt = sc.nextInt(); // 첫 번째 파일이름 char[] creteria = sc.next()..

Iterator 그리고 Iterable에 대해 정리
Java8의 Stream에 map 기능을 사용하다가 이런문제를 겪었다. Iterable과 Iterator 정확한 정리를 하지 않고 무턱대고 사용하다보니 발생한 문제였다. 정확하게 집고 넘어가기 위해 정리해보자. Iterator Iterator는 자바 1.2에 발표된 인터페이스이다. hasNext, next 등을 통해 현재 위치를 알 수 있고 다음 element가 있는지를 판단하는 기능등에 대한 명세를 제공한다. 이를 사용하기 위해서는 Iterator 인터페이스의 내용을 직접 구현해야 한다. 대게 Collection 인터페이스를 사용하는 클래스의 경우 별도의 Iterator를 구현하여 사용하고 있다. 밑에 Iterable을 설명하면서 정리해보자. 123456789101112public interface I..

static method와 Override hiding 대한 정리
static 메소드를 자기고 있는 클래스를 상속받은 자식 클래스에서 그 static 메소드를 override 할 수 있을까? 안될거 알지만 한번 확인해보고 싶었다. 먼저 static method를 가지고 있는 Parent을 만들었다. 123456789101112/** * 부모 클래스 */static class Parent { public static void getData() { System.out.println("부모 getData"); } public void method() { System.out.println("부모 method"); }}Colored by Color Scriptercs 그리고 이를 상속하는 Child 클래스를 만들어보자.123456789101112/** * 자식 클래스 */sta..

백준 1094 막대기 문제
문제 내용 https://www.acmicpc.net/problem/1094소스코드자세한 소스는 참고 https://github.com/weduls/algorithm/tree/master/%EC%8B%9C%EB%AE%AC%EB%A0%88%EC%9D%B4%EC%85%98/%EB%A7%89%EB%8C%80%EA%B8%B0 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768import java.util.Scanner;import java.util.Stack;import java.util.stream.IntStream; public cl..