부하분산

Kafka 정리
카프카는 분산형 스트리밍 플랫폼으로써 다음으로 정의할 수 있다. 메시지 큐와 유사하게 스트림을 publish하고 subscribe 하는 방식이다.fault-tolerant 지속 방식으로 레코드들의 스트림들을 저장한다. 용도 시스템이나 어플리케이션에서 발생한 실시간 스트리밍 데이터를 안정적으로 데이터 파이라인 구축할 때데이터 스트림을 전송하거나 처리해야할 때 사용 구성 하나이상에 서버에 여러 cluster로 구성되어 있다.topic이라는 카테고리로 레코드 스트림들을 저장한다.각각의 레코드들은 key, value, timestamp로 구성되어 있다. 핵심 APIProducer API하나 또는 그 이상의 카프카 topic을 데이터 스트림에 발행할 수 있도록 해주는 APIConsumer API어플리케이션이 하나..
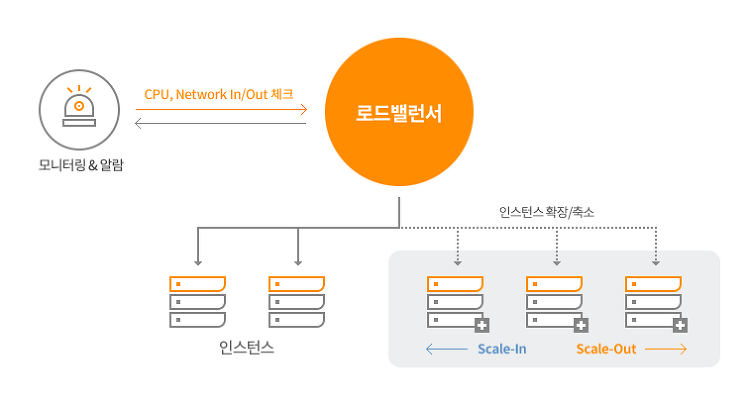
오토 스케일링(Auto Scaling) 소개
클라우드 환경이 대세다. 솔직히 말하면 대세인건 알지만 간단하게 aws 내 작은 서버 하나를 사용하고 있는 정도만 사용하고 있다. 아니 물론 SaaS 프로그램은 많이 사용하고 있지만 실질적으로 클라우드 환경이 어떻게 구성되고 있는지는 자주 사용하지 않아 100% 다 알지 못한다. 그래서 공부를 더욱 열심히 하고 있고 오늘은 오토 스케일링에 대해 알아보자. #오토스케일링 서버를 운영하다보면 갑작스럽게 트래픽이 몰리는 경우가 있다. 예를 들면 이벤트를 한다거나 특정 티켓이 오픈되는 경우가 될 수 있다. 이런 경우에 서버의 자원이 자동으로 확장되어 트래픽에 대응할 수 있다면 얼마나 좋을까? 이때 사용되는 기술이 오토 스케일링이다. 사용자가 미리 지정한 오토 스케일링 정책에 따라 트래픽이 발생하였을 때 미리 지..

파티셔닝의 정의와 종류 그리고 샤딩
샤딩과 파티셔닝 DB 보안 회사를 다니고 있고 대규모의 서비스가 기본인 현 시대에 파티셔닝과 샤딩에 대해 많이 들었지만 자세히 알지는 못했다. 이번기회에 한번 정리를 해보자. #파티셔닝 파티셔닝은 퍼포먼스, availability, maintainablity를 목적으로 논리적인 데이터를 다수의 엔티티로 분할하는 행위를 뜻한다. 대부분의 DBMS에서 지원하지만 Mysql 5.1 미만에서는 지원하지 않는다. 샤딩 또한 이 파티셔닝의 한 종류이다. 수평 파티셔닝 (horizotal partitioning, Range Based Partitioning) 샤딩과 동일한 의미를 가지며 스키마를 다수의 복제본을 구성하고 각각의 샤드에 샤드키를 기준으로 데이터를 분리하는 것을 말한다. DBA가 데이터의 패턴과 저장공간..