
자바 메모리 구조는 1.8 이후로 일부분 바뀌었다.
이 부분에 대한 정리를 다시 하고 싶었고 GC 알고리즘에 대한 종류와 상세 내용을 정리하고 싶었다. 그럼 이 두 가지 사항에 대해 가볍게 정리해보자.
Java 메모리 구조
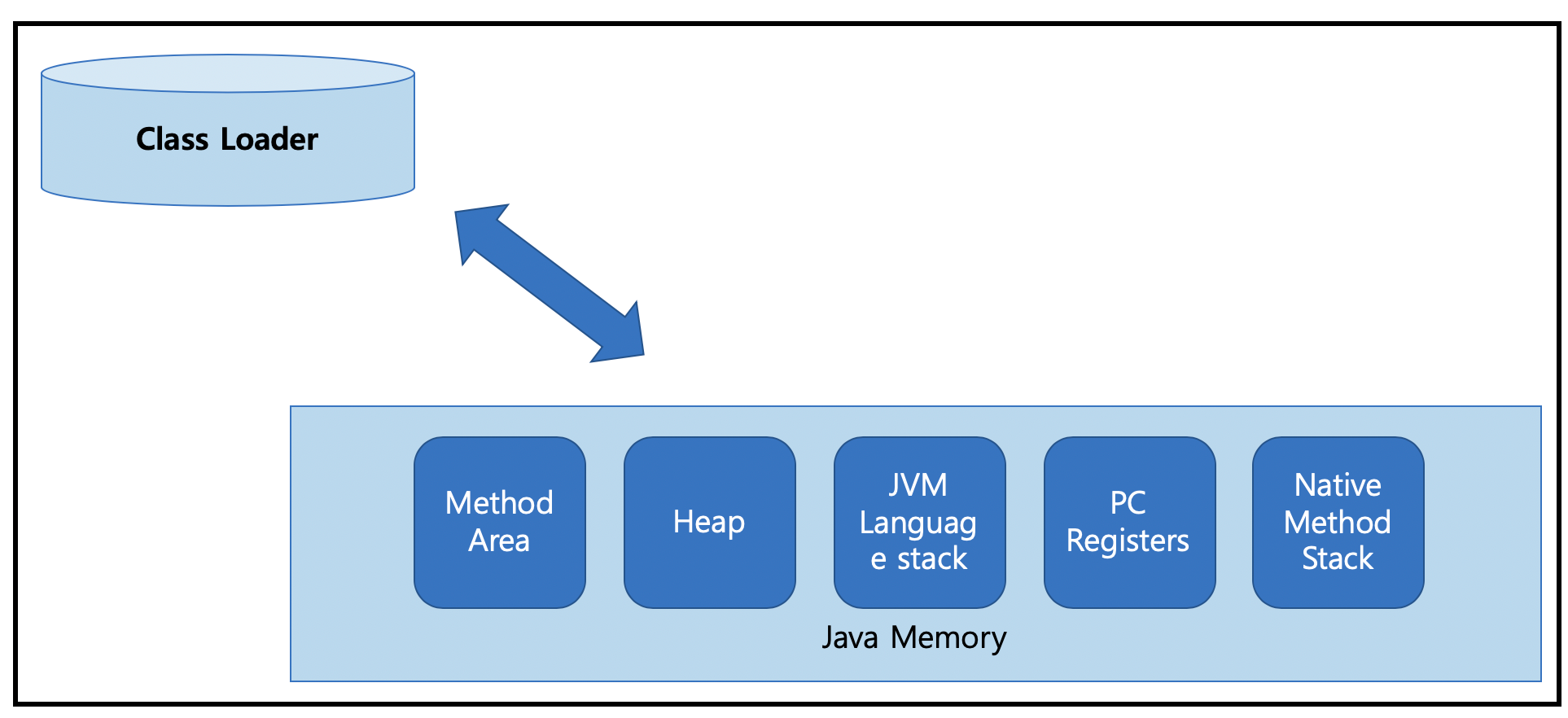
Method Area
프로그램이 실행되는 도중에 아직 사용되지 않은 클래스들의 코드는 new를 통해 클래스의 인스턴스가 생성되면 JVM Method Area에 인스턴스 변수, 메스드 코드, 클래스 변수등을 저장한다. 해당영역은 모든 쓰레드 사이에서 공유되고 static 키워드로 생성된 변수 또한 저장을 Runtime Constant Pool 영역에 저장한다. 실 데이터를 저장하는 것이 아니라 레퍼런스만 저장하며 실제 데이터는 Heap 영역에 저장한다.
JVM Language stack
각 스레드들은 생성과 동시에 각자의 stack을 생성하게 되는데 이 영역에 메소드가 실행될 때 사용된 메스드의 데이터들을 저장한다. 그리고 메서드 실행이 끝나면 해당 stack영역은 사라진다.
PC Registers
각 스레드별로 PC Registers가 존재하며 JVM 머신이 가장 최근에 실행한 명령어의 주소를 저장한다.
Native Method Area
Native Library에 의존하는 native 코드들을 저장하는 곳이다. (JNI)
Permenent (Java8 metaspace 대체)
permenent 영역에 로드된 클래스의 메타 정보와 static한 변수들 정보들이 담겨져 있는데 그 중 static 영역과 상수 영역은 heap으로 옮겨졌다.
-XX:MetaspaceSize : JVM이 사용하는 네이티브 메모리
-XX:MaxMetaspaceSize : metaspace의 최대 메모리
Heap 영역
GC가 발생되는 대표적인 영역이며 new를 통해 인스턴스가 동적으로 생성된 데이터와 배열정보를 저장하는 공간으로 xms, xmx등의 옵션으로 기본 힙사이즈를 설정할 수 있다. 해당 힙사이즈도 모든 쓰레드 사이에서 공유된다.
-Xms : JVM 시작 시 힙 영역 크기
-Xmx : 최대 힙 영역 크기
힙 영역은 GC가 발생되는 방법에 따라 Young, Old영역으로 나뉘게 된다.
1. Young 영역
Eden
새롭게 할당된 데이터가 쌓이는 곳으로 일정주기 동안 참조가 유지되면 Survivor로 옮겨진다. Survivor로 옮겨지지 못한 데이터는 GC에 의해 청소된다.
Survivor
Eden영역에서 넘어온 데이터가 1 또는 2영역으로 나눠서 저장된다. 참조가 살아있는 경우 주기에 맞춰서 다른 Survivor영역으로 이동하고 그렇지 못한 데이터들은 GC에 의해서 처리된다. 위와 같은 경우를 Minor GC라고 한다.
-XX: NewRatio : New영역과 Old 영역의 비율
-XX: NewSize : New 영역의 크기
-XX: SurvivorRatio : Eden 영역과 Survivor 영역의 비율
2. Old 영역
Survivor 영역에서 오래 살아남은 데이터의 경우 Old 영역으로 넘어가게 된다. Old 영역은 이렇게 넘어온 데이터가 많기 때문에 Young크기 보다 더 크게 설계되며 이부분에서 발생된 GC를 Major GC라고 한다.
GC 알고리즘
YOUNG, OLD GC가 발생되는 알고리즘 종류에 대해 정리해보자. 우선 GC의 경우 mark > sweep > compaction 작업이 순서대로 동작한다. 우선 GC 대상을 고르는 mark 작업이 선행되고 실제 제거를 수행하는 sweep가 동작한다. 그리고 메모리의 파편화가 된 부분을 채워 나가는 Compaction 작업으로 마무리한다.
Serial GC
위에서 언급한 3가지 작업이 진행되는 간단한 GC 알고리즘이다. 이 GC의 경우 처리하는 쓰레드가 단 하나이기 때문에 처리하는 과정 동안에 발생하는 STW (Stop the world) pause 시간이 길다.
Parallel GC
Serial GC에서 동작하는 스레드가 하나였기 때문에 문제가 자주 발생하였는데, 여기에 작업을 진행하는 스레드를 추가하여 병렬로 작업을 진행한 알고리즘 이다.
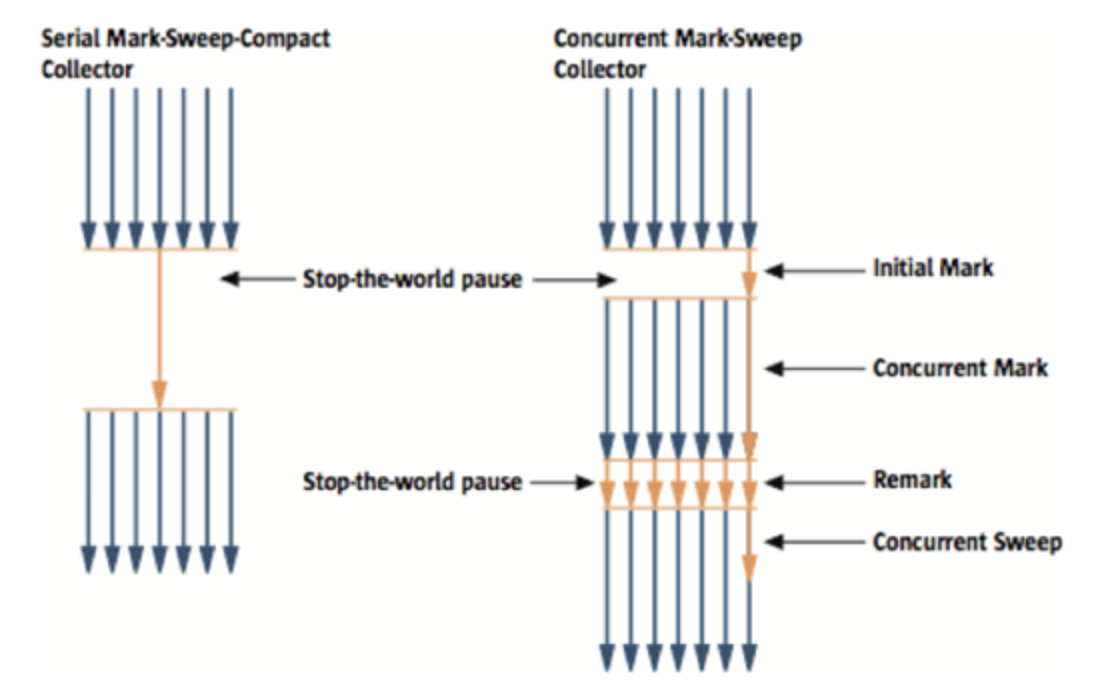
CMS GC
기존에 사용되던 GC 알고리즘 보다 STW pause 시간을 줄이기 위해 고안된 방법으로 없애야 하는 데이터를 정확하게 선별하는 작업이 추가로 진행된다. 그만큼 연산작업이 추가되어 CPU같은 리소스 자원 사용이 증가하였다. 최초 GC 판단하는 initial Mark, initial mark때 선정된 객체를 참조 하는 객체의 GC 대상인지 판단하는 Concurrent Mark, 마지막 검증 작업을 하는 Remark작업을 통해 대상을 선정한 후 Concurrent Sweep 작업을 통해 데이터를 지운다. 그리고 기존 Serial GC와의 차이점은 데이터를 sweep한 후 compaction 작업을 자주 진행하지 않는다. 파편화된 메모리를 자주 매꾸면 그만큼 오버헤드가 많이 발생할 수 있기 때문에 심각한 파편화가 발생했을 때만 매꾼다.
G1GC
기존에 GC 알고리즘과는 다른 알고리즘이 나온게 G1GC이다. 기존에는 Eden, Survivor, Old, Permanent영역으로 정확하게 나누어져 있었다. 하지만 G1GC 사용할 경우 heap 영역을 2048개 region 영역으로 쪼개고 이 지역의 크기는 G1HeapRegionSize를 통해 32mb 까지 지정이 가능하다.
또한 새로운 형태의 상태값이 생겼는데 Humongous와 Available/Unused이다. Humongous는 region크기의 50%를 초과하는 큰 데이터를 저장하기 위한 곳이고 Available/Unused는 아직 사용하지 않는 region을 뜻 한다.
각 Region은 Eden, Survivor, Old, Permanent, Humongous, Available/Unused 상태로 지정이 가능하고 데이터가 가장 많이 찬 Region에서 GC가 발생된다.

출처
https://www.guru99.com/java-virtual-machine-jvm.html
https://d2.naver.com/helloworld/1329
'JAVA > 고급 자바' 카테고리의 다른 글
| 문자열 연결 시 실행되는 내부 로직 (0) | 2022.10.31 |
|---|---|
| 모던 자바 인 액션 내용 정리 (0) | 2020.04.12 |
| [공유] 자바 유료화 관련 글 공유 (0) | 2018.10.04 |
| Iterator 그리고 Iterable에 대해 정리 (0) | 2018.10.04 |
| static method와 Override hiding 대한 정리 (0) | 2018.10.04 |