데이터베이스
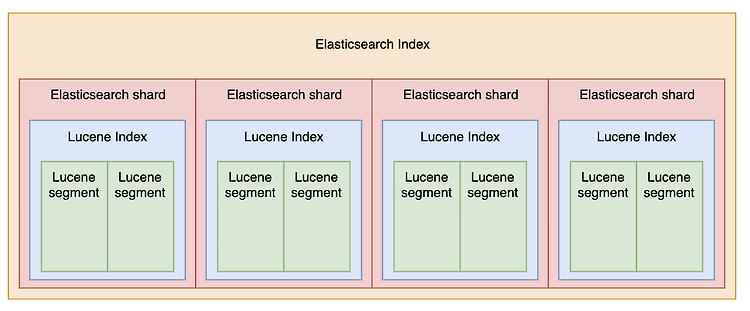
Lucene의 segment가 immutable한 이유
Elasticsearch의 Document의 수정, 삭제 동작이 발생되었을 때 실제 Document를 구성하고 있는 각 shard 내부 Segment는 바로 지워지지 않는다. 대신 해당 세그먼트가 지워졌다고 mark만 하고 수정되었을 경우에는 새로운 세그먼트를 할당한다. 이렇게 동작하는 이유는 Lucene레벨에서 비용을 아끼기 위해서 사용된다고 알고는 있었는데 정확하게 왜 segment가 immutable한지 알지 못해서 정리해 봤다. 1. 동시성 이슈 우선 개인적으로 생각했을 때는 immutable한 데이터의 경우 수정에 의한 고민을 할 필요가 없기 때문에 multi thread 환경에서 특별한 race condition을 고려할 필요가 없어서 이점이 있다고 생각했다. 우연한 기회에 해당 부분에 대해 ..
Elasticsearch의 Translog 설명
Lucene을 공부하면서 실제 세그먼트를 조작 하고 인덱싱을 반영 하는 부분을 보면서 Lucene에 commit에 대해서 공부했었다. wedul.site/678 Lucene의 commit과 flush의 차이 Lucene에서 데이터 색인을 위해서 사용하는 IndexWriter의 flush와 commit 두 가지 command의 차이를 정리해보자. 두 개의 operation 이름만 보게되면 동일한 동작을 수행할 것 같지만 실질적으로 다른 동작을 wedul.site 그럼 실제로 Elasticsearch에서 이 Lucene commit에 영향을 받는 부분이 어디인지 알아보게 되면서 translog에 대해 공부해봤다. 우선 translog는 양 자체가 워낙 방대하기 때문에 성능을 위해서는 이 부분에 대한 튜닝이 ..
Lucene의 commit과 flush의 차이
Lucene에서 데이터 색인을 위해서 사용하는 IndexWriter의 flush와 commit 두 가지 command의 차이를 정리해보자. 두 개의 operation 이름만 보게되면 동일한 동작을 수행할 것 같지만 실질적으로 다른 동작을 수행한다. 우선 공통적으로 commit과 flush는 둘 다 메모리에 있는 데이터를 디스크에 쓰는 작업을 한다. 하지만 이 부분에 차이점이 있는데 commit은 인덱스를 업데이트하여 디스크에 데이터를 바로 찾을 수 있도록 하는 추가작업을 수행한다. 그래서 만약 lucene IndexWriter에서 flush만 수행하고 commit을 하지 않았다면 해당 인덱스에 대한 변경사항은 검색할 수 없다. 그렇다면 commit을 수행하고 flush를 하지 않는다면 어떻게 될까? 이 ..
Lucene 기본, 색인, 성능 최적화 정리
용어 정리 재현율 검색 시스템에서 관련된 문서를 얼마나 빼먹지 않고 찾아두는지 정확도 검색 시스템에서 사용자가 입력한 검색어와 관련없는 문서를 얼마나 정확하세 제거 하는지 fuzzy 레빈슈타인 편집거리를 통해서 입력한 텀과 유사한 텀을 가진 문서를 찾아줌 비교되는 두 단어의 추가, 수정, 삭제에 대한 비용 처리를 하며 비용이 높을수로 서로 다른 term 검색 모델 순수 boolean 모델 지정된 질의에 문서가 해당하는지 아니면 해당하지 않는지를 판단하며 별도의 계산 부분이 없다. 벡터 공간 모델 질의와 문서 모두 고차원(차원은 term을 의미)의 벡터로 표현. 벡터간의 거리를 계산하면 문서와 질의 사이의 연관도나 유사도를 산출 할 수 있다. 확률모델 확률적인 방법을 통해 개별 문서가 질의와 일치하는 확률..
elasticsearch metric 수집 방법
Elasticsearch metric 정보 수집관련해서 요근래 질문을 받았었다. 처음에는 java application이라면 기본적으로 생각하는 JMX metric을 고려했었으나 그때 당시에 이 community를 보고 직접 aggregation해서 influxdb에 수집하는 방법을 선택했던게 생각난다. (실제로 내 입장에서는 jmx로 metric 정보를 보는게 너무 불편했다.) 또 aggregation할 때 spring actuator micrometer를 사용하려 했으나 이곳에서 모으는 데이터를 정제해서 보고자 하는 데이터 형태로 influxdb에 넣는건 좋지 못한 방법이었다. 그래서 결국 pooling방식으로 얻고자 하는 클러스터에 직접 stats관련된 http api를 요청해서 잘 조립해서 inf..
[번역] 2-2. Domain 모델 (Enum, UUID, Date, Attribute, Generated Properties)
2.3.7 Enums 매핑 Hibernate는 기본값 유형으로써 다양한 방법으로 Java Enum의 매핑을 지원한다. @Enumrated 기본적인 JPAdml enums의 매핑 방법은 @Enumrated 또는 @MapKeyEnumrated 애노테이션을 통해 javax.persistence.EnumType에 표시된 두 가지 전략 중 하나에 따라 enum 값이 저장된다는 원칙에 따라 동작한다. ORDINAL - java.lang.Enum#ordinal에 기재된대로 Enum 클래스 내에서 Enum값의 순서에 따라 저장된다 STRING - java.lang.Enum#name 방식에 기재에 따라 Enum값의 이름에 따라서 저장된다. 아래 예시로 PhoneType이라는 Enum이 있다고 가정해보자. public e..
![[번역] 2-1. Domain 모델 (매핑 타입, 네이밍 전략, Basic Type - 1)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F4YlPG%2FbtqMkmvxqOy%2Fu7aQTvoxN5I0HYEjvK38k0%2Fimg.png)
[번역] 2-1. Domain 모델 (매핑 타입, 네이밍 전략, Basic Type - 1)
2. 도메인 모델 도메인 모델이라는 단어는 데이터 모델링이라는 영역에서 비롯된다. 이것은 작업을 하고 있는 도메인의 모델로 묘사되기도 하고 때때로 이를 persistent classes라고 부른다. 궁극적으로 애플리케이션 도메인 모델은 ORM에서 중심이 되는 단어이다. 이것들은 매핑하고 싶은 클래스들로 구성된다. Hibernate는 POJO/JAVA Bean 프로그래밍 모델을 따를 때 가장 잘 동작한다. 그러나 이런 규칙은 어려운 요구사항은 아니다. 게다가 Hibernate는 persistence 객체의 특성에 대해 매우 조금만 담당하고 있다. 사실 Map 인스턴스 트리등을 사용하여 다른 방법으로도 domain 모델 구현이 가능하다. 2.1 매핑 타입 Hibernate는 Java와 JDBC 애플리케이션의..
![[번역] Hibernate Document 서문, 시스템 요구사항, 아키텍처](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbPceF5%2FbtqLf6azeUP%2Fy8P5v0EjOQlJ1XkVfIpgl1%2Fimg.png)
[번역] Hibernate Document 서문, 시스템 요구사항, 아키텍처
서문 객체 지향 소프트웨어와 관계형 데이터베이스를 함께 쓰는 것은 귀찮고 시간이 많이 소비된다. 데이터가 관계형 데이터베이스와 객체 사이에서 표현되는 방식의 패러다임 불일치로 인해 개발 비용이 증가하게 된다. Hibernate는 자바 환경에서 객체/릴레이션 매핑의 솔루션이다. 객체/관계형 매핑이라는 말은 객체 모델 표현 방식으로 부터 관계형 데이터를 매핑하는 기술을 의미한다. Hibernate는 자바 클래스로 데이터베이스를 매핑하는 것 뿐 아니라 데이터 쿼리 및 탐색 기능을 제공한다. 이는 SQL과 JDBC로 데이터를 핸들링하는 시간을 상당히 줄여줄 수 있다. Hibernate의 디자인 목표는 SQL과 JDBC로 데이터를 처리하는 필요성을 제거함으로써 개발다의 데이터 관련 프로그램 작업의 95% 감소 시..

Mysql 인덱스 사용법 및 실행 계획 정리
mysql 인덱스에 대한 정확한 이해도 없이 사용을 하다보니 조금 개념적으로 헷갈리는게 많이 있었다. 이 부분에 대해 한번 정리하고 넘어가고자 기록해본다. 인덱스 인덱스는 빠르게 특별한 컬럼과 함께 값을 찾는데 사용된다. 인덱스가 없으면 Mysql은 처음 행부터 전체 테이블을 읽어 들여서 데이터를 찾는다. 거대한 테이블에서 이런 행동은 비용이 상당히 많이 들어가게 된다. 만약에 테이블이 인덱스를 가지고 있으면 빠르게 접근할 수 있게 된다. 대부분의 Mysql 인덱스 (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT)는 B-tree안에 저장된다. 예외적으로 spatial 데이터 타입은 R-tree를 사용, 메모리 테이블은 또한 hash index를 지원, InnoDB는 FULLTE..

Elasticsearch 7.7 feature와 heap 메모리 사용량의 두드러진 감소량
줄어든 heap 사용량Elasticsearch 사용자들은 Elasticsearch 노드에 저장이 가능한 만큼 데이터를 집어 넣지만, 가끔 disk에 저장되기 전에 heap memory 사용량이 초과되는 것을 경험한다. 이는 비용을 줄이기 위해 가능한 노드당 많은 양의 데이터를 넣고 싶은 사용자들에게 문제를 일으킨다. (실제로 현재 운영중인 es에서도 대량의 데이터 삽입 시 가끔 발생함) 왜 Elasticsearch에는 데이터를 저장하기 위해 heap memory 영역이 필요한걸까? 왜 디스크 공간만으로 충분하지 않은걸까?? 거기에는 여러 이유가 존재하지만 가장 중요한 이유는 루씬은 디스크 상에 데이터를 찾을 수 있는 위치를 찾아내기 위해서 일부 정보를 메모리에 저장해야 한다. 예를 들어 루씬의 inver..